

Main takeaways
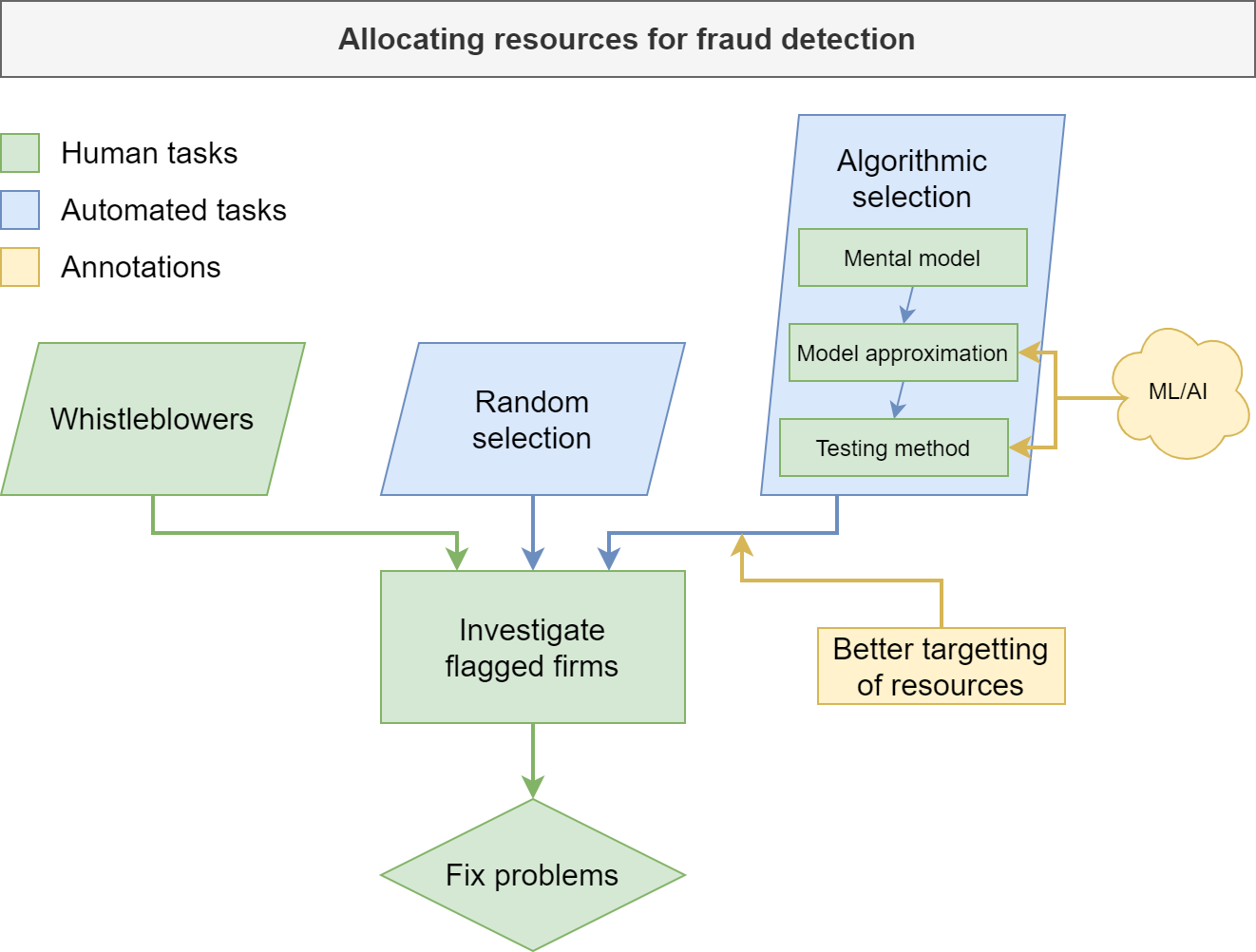
#1: Machine learning can help unlock new fraud detection features
- Machine learning lets you build measures that more closely map to your mental model
- Often times these features could be manually coded, but at the expense of hundreds to thousands of hours of work
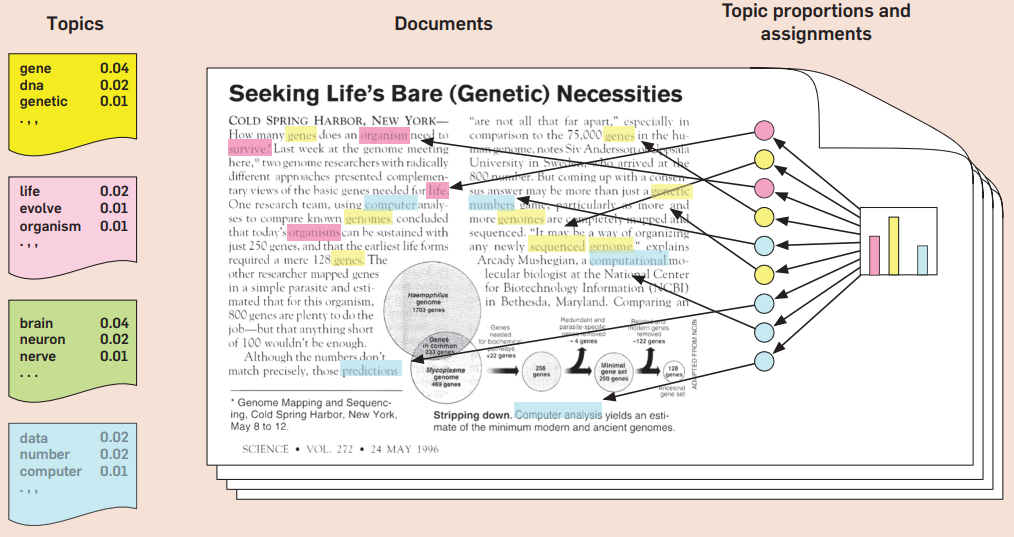
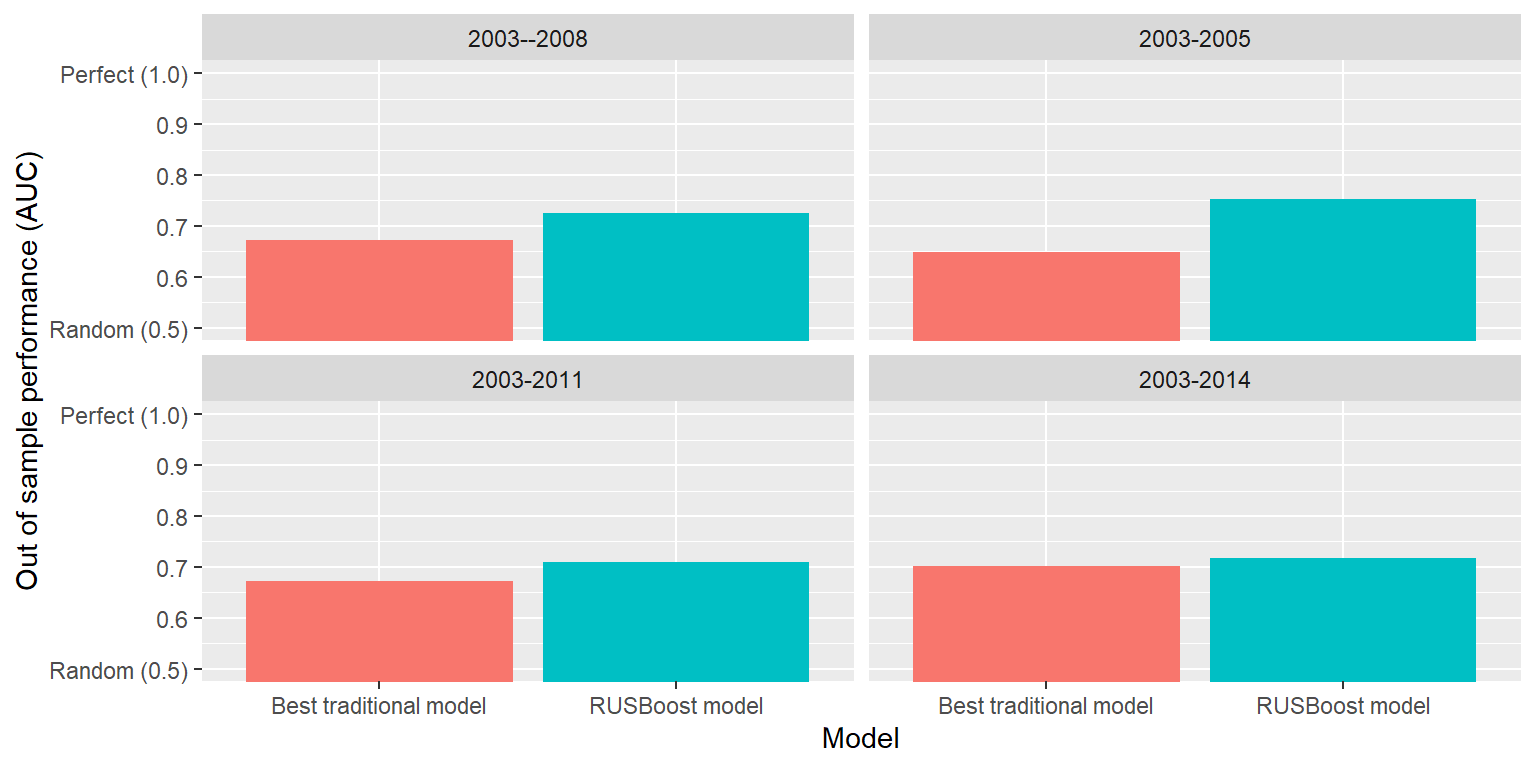
#2: Machine learning provides new ways to leverage existing data
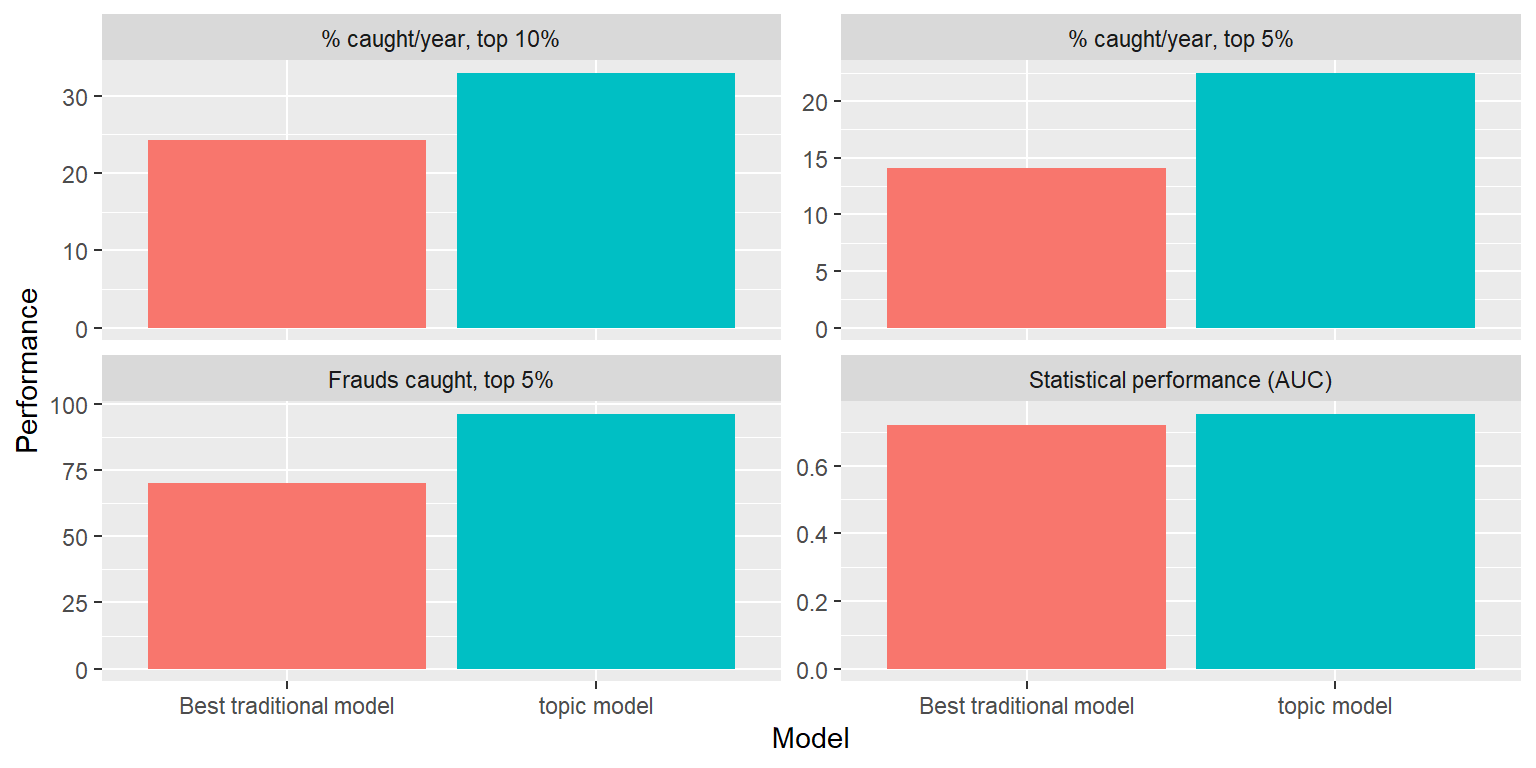
- Even with the same data and measures, we can get better predictive ability, particularly when trying to detect sparse events (<10% frequency)