Main question
Can we use bankruptcy models to predict supplier bankruptcies?
But first:
Does the Altman Z-score [still] pick up bankruptcy?


df %>%
filter(!is.na(Z),
!is.na(bankrupt)) %>%
group_by(bankrupt) %>%
mutate(mean_Z=mean(Z,na.rm=T)) %>%
slice(1) %>%
ungroup() %>%
select(bankrupt, mean_Z) %>%
html_df()| bankrupt | mean_Z |
|---|---|
| 0 | 3.939223 |
| 1 | 0.927843 |
df %>%
filter(!is.na(Z),
!is.na(bankrupt),
year >= 2000) %>%
group_by(bankrupt) %>%
mutate(mean_Z=mean(Z,na.rm=T)) %>%
slice(1) %>%
ungroup() %>%
select(bankrupt, mean_Z) %>%
html_df()| bankrupt | mean_Z |
|---|---|
| 0 | 3.822281 |
| 1 | 1.417683 |
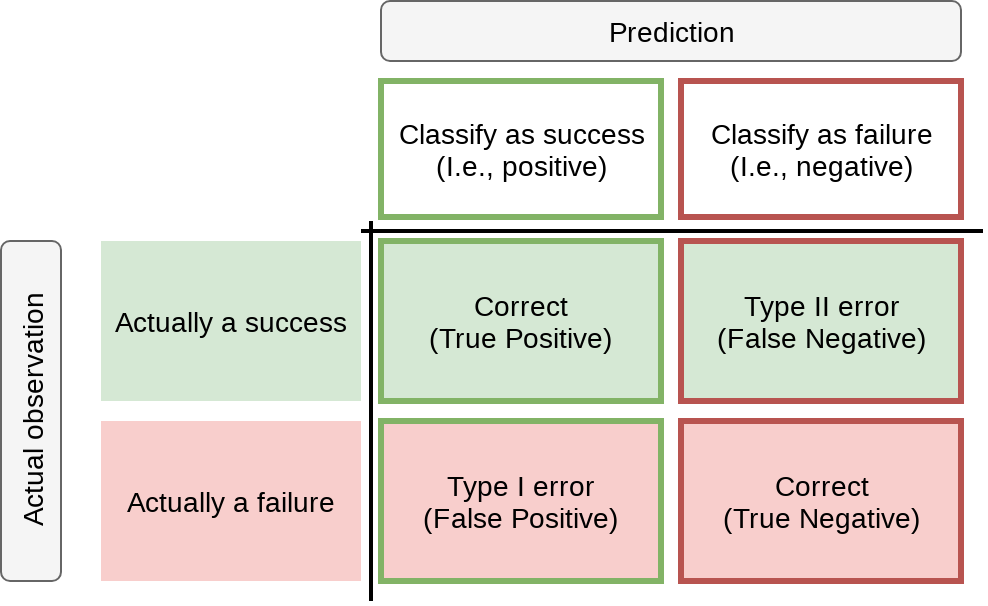
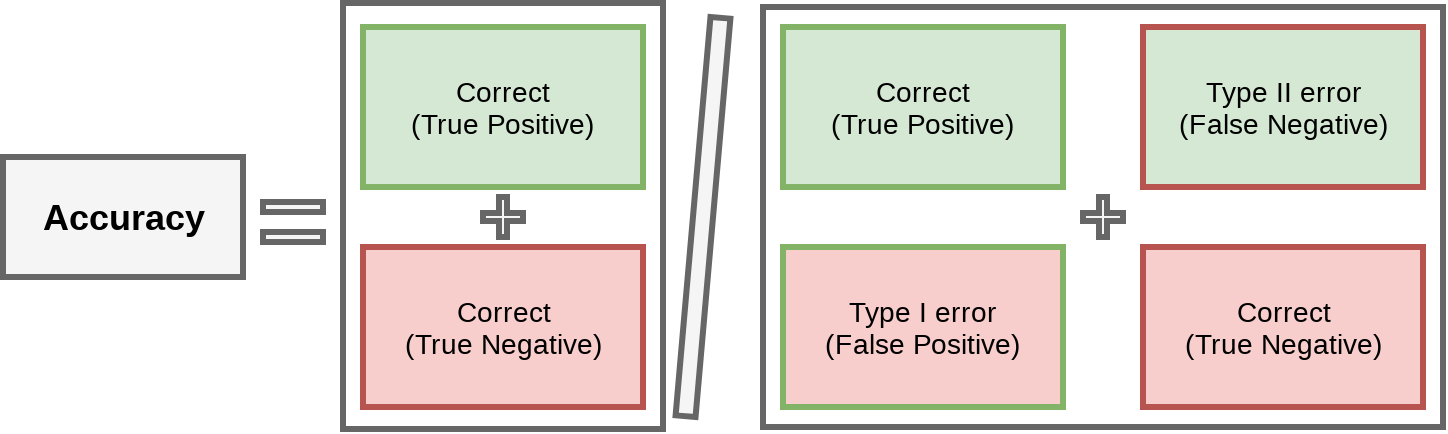
This type of chart (filled in) is called a Confusion matrix
We say that the company will go bankrupt, but they don’t

We say that the company will not go bankrupt, yet they do


df_ROC_Z <- data.frame(
FP=c(ROCperf_Z@x.values[[1]]),
TP=c(ROCperf_Z@y.values[[1]]))
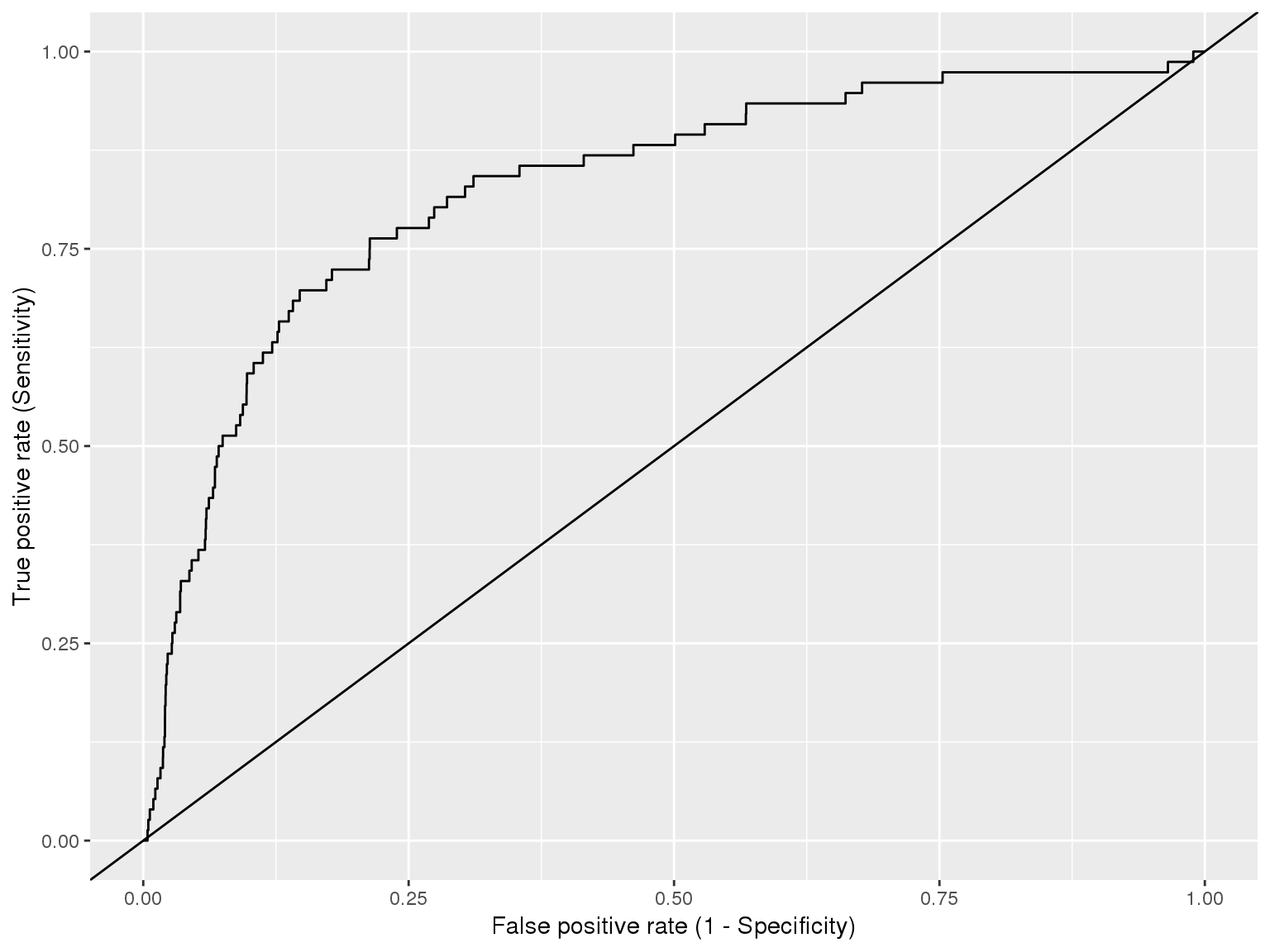
ggplot(data=df_ROC_Z,
aes(x=FP, y=TP)) + geom_line() +
geom_abline(slope=1)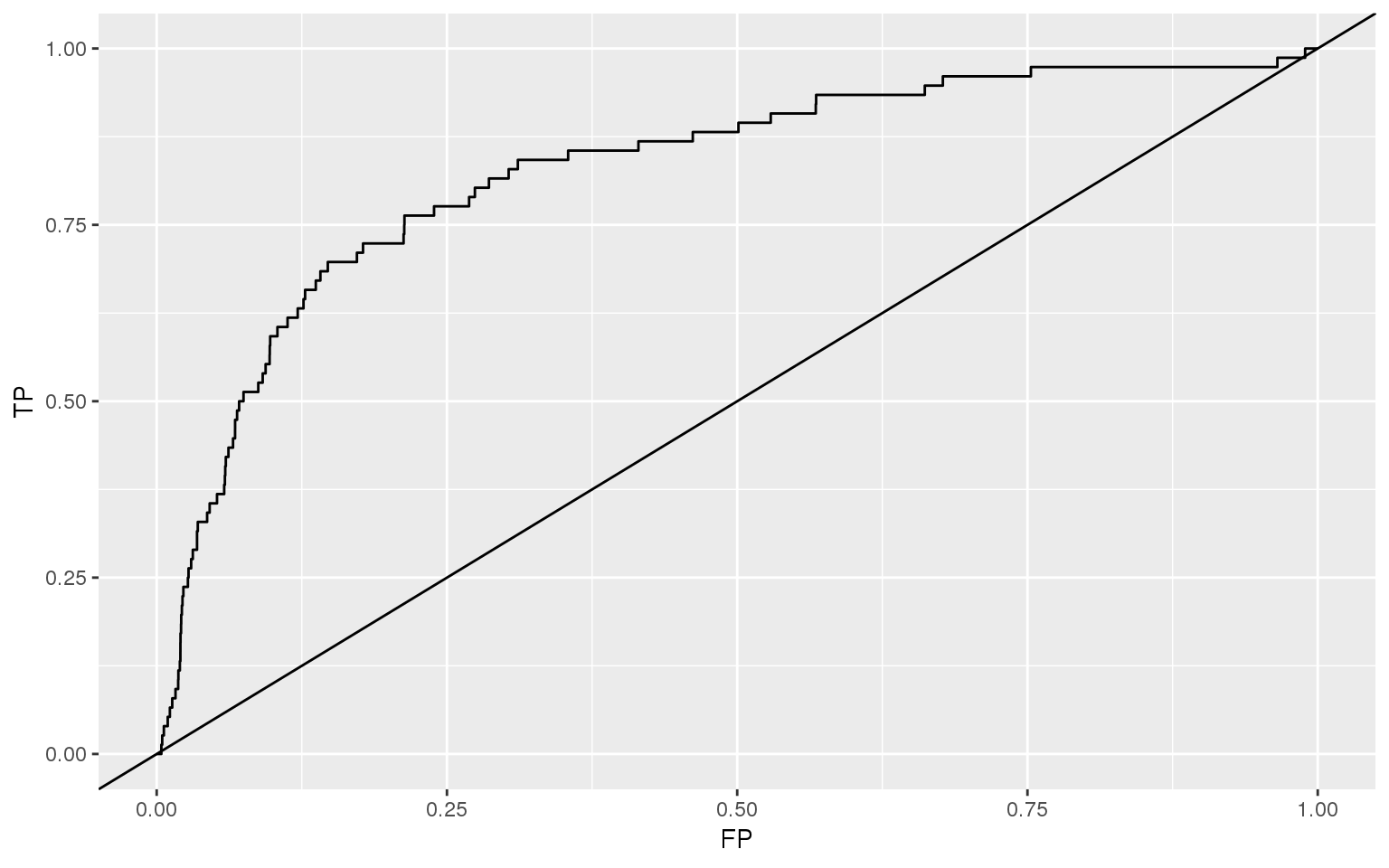
plot(ROCperf_Z)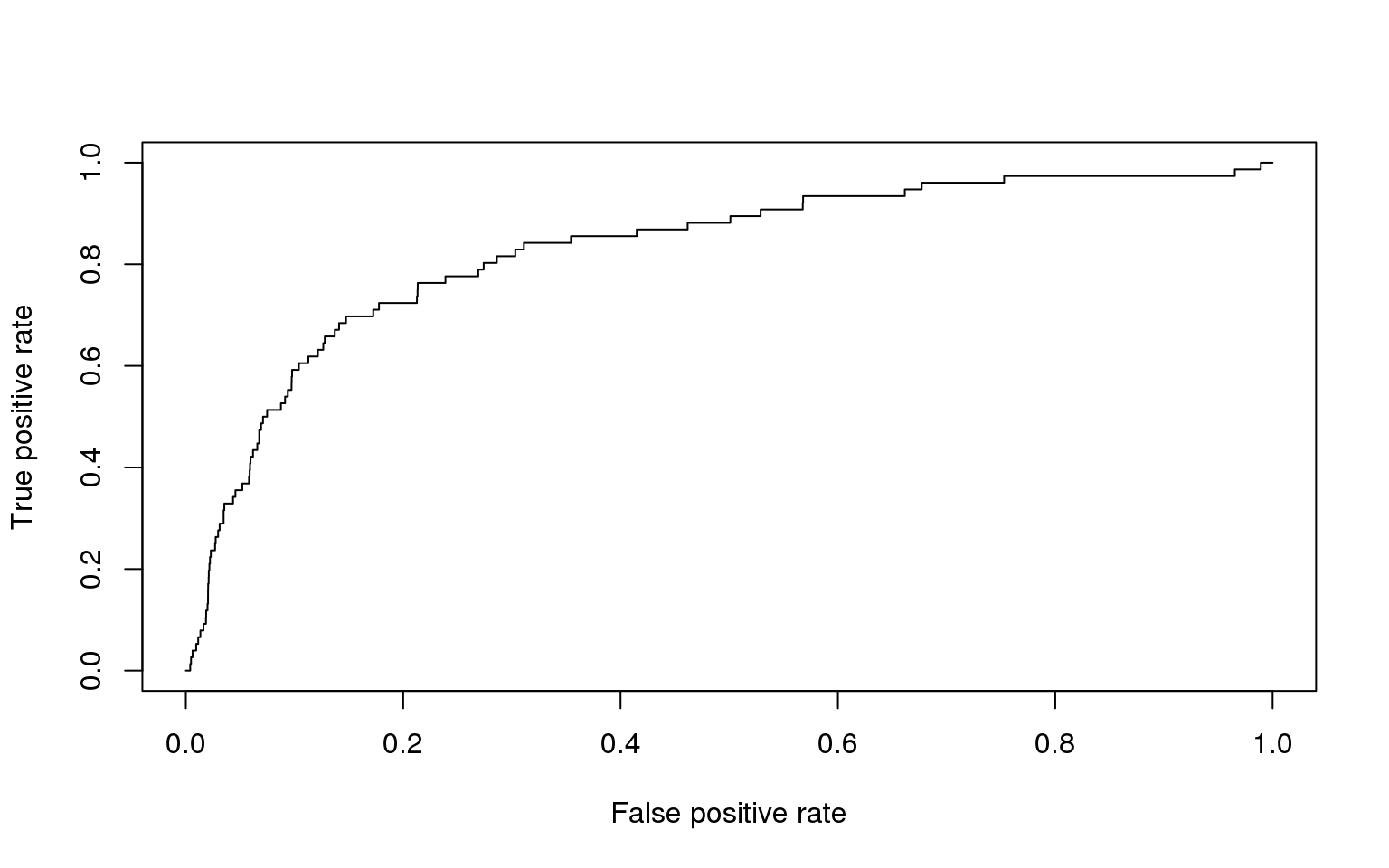

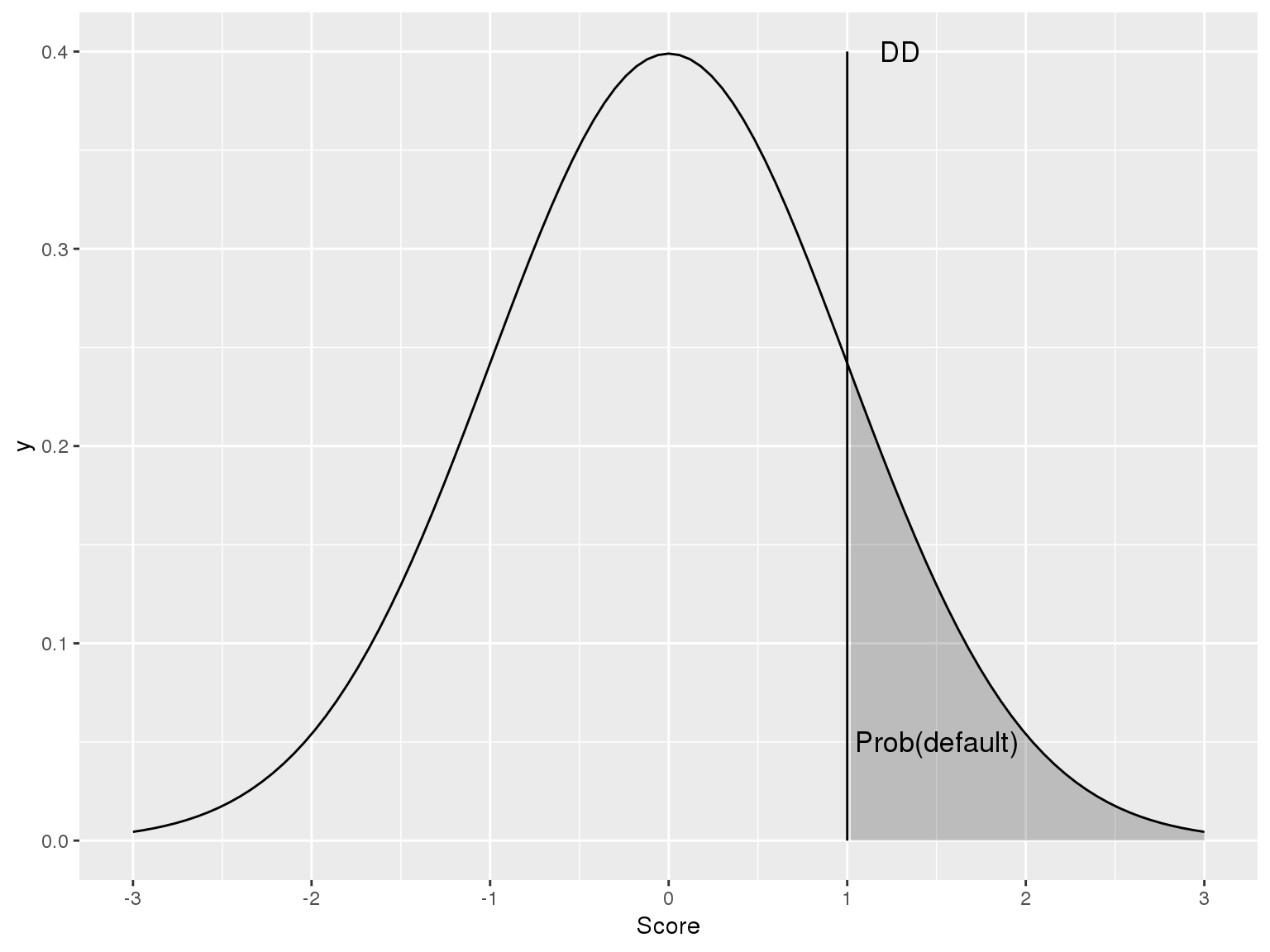
DD = \frac{\log(V_A / D) + (r-\frac{1}{2}\sigma_A^2)(T-t)}{\sigma_A \sqrt(T-t)}

df %>%
filter(!is.na(DD),
!is.na(bankrupt)) %>%
group_by(bankrupt) %>%
mutate(mean_DD=mean(DD, na.rm=T),
prob_default =
pnorm(-1 * mean_DD)) %>%
slice(1) %>%
ungroup() %>%
select(bankrupt, mean_DD,
prob_default) %>%
html_df()| bankrupt | mean_DD | prob_default |
|---|---|---|
| 0 | 0.612414 | 0.2701319 |
| 1 | -2.447382 | 0.9928051 |
df %>%
filter(!is.na(DD),
!is.na(bankrupt),
year >= 2000) %>%
group_by(bankrupt) %>%
mutate(mean_DD=mean(DD, na.rm=T),
prob_default =
pnorm(-1 * mean_DD)) %>%
slice(1) %>%
ungroup() %>%
select(bankrupt, mean_DD,
prob_default) %>%
html_df()| bankrupt | mean_DD | prob_default |
|---|---|---|
| 0 | 0.8411654 | 0.2001276 |
| 1 | -4.3076039 | 0.9999917 |
pred_DD <- predict(fit_DD, df, type="response")
ROCpred_DD <- prediction(as.numeric(pred_DD), as.numeric(df$bankrupt))
ROCperf_DD <- performance(ROCpred_DD, 'tpr','fpr')
df_ROC_DD <- data.frame(FalsePositive=c(ROCperf_DD@x.values[[1]]),
TruePositive=c(ROCperf_DD@y.values[[1]]))
ggplot() +
geom_line(data=df_ROC_DD, aes(x=FalsePositive, y=TruePositive, color="DD")) +
geom_line(data=df_ROC_Z, aes(x=FP, y=TP, color="Z")) +
geom_abline(slope=1)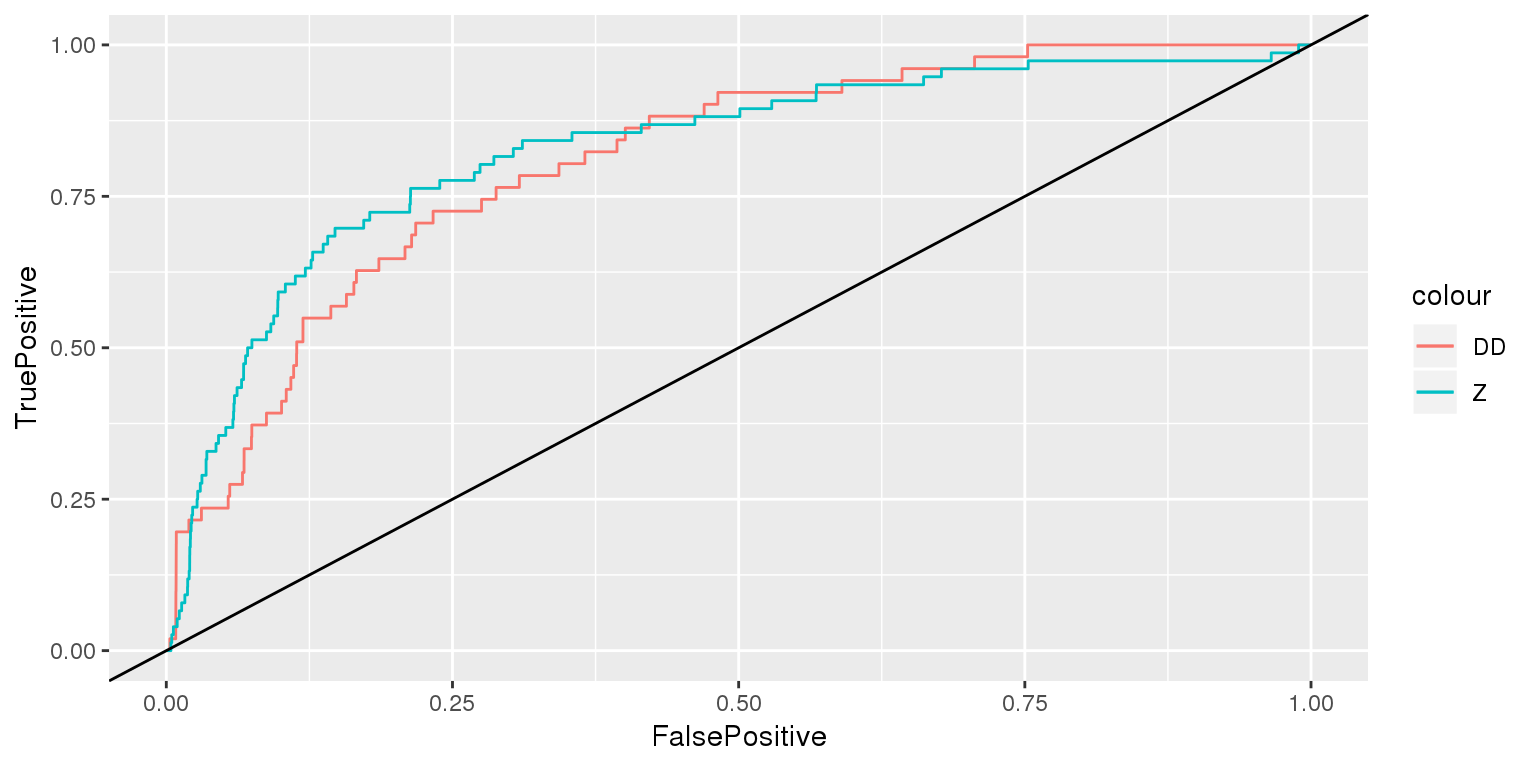
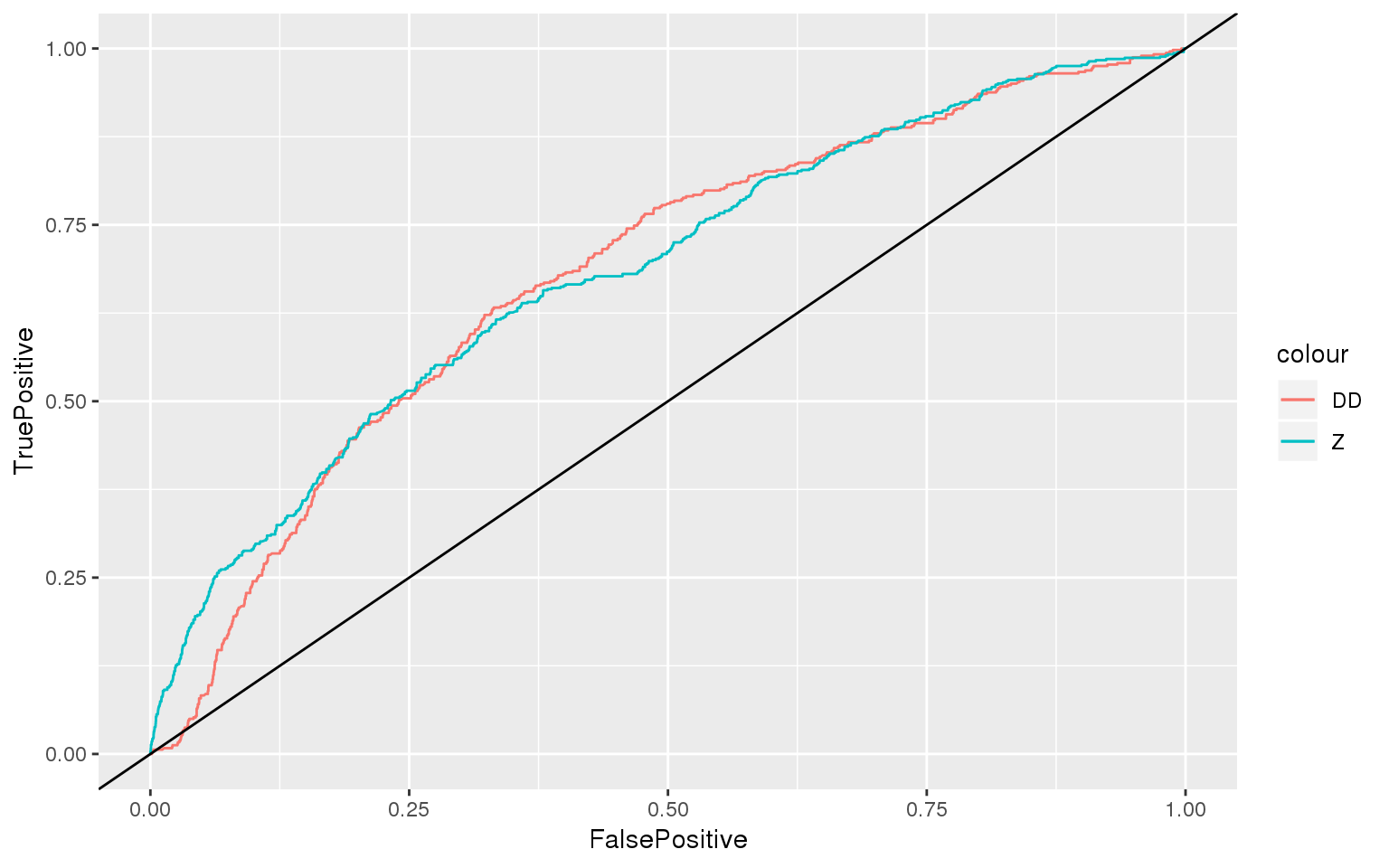
## Z DD
## 0.6839086 0.6811973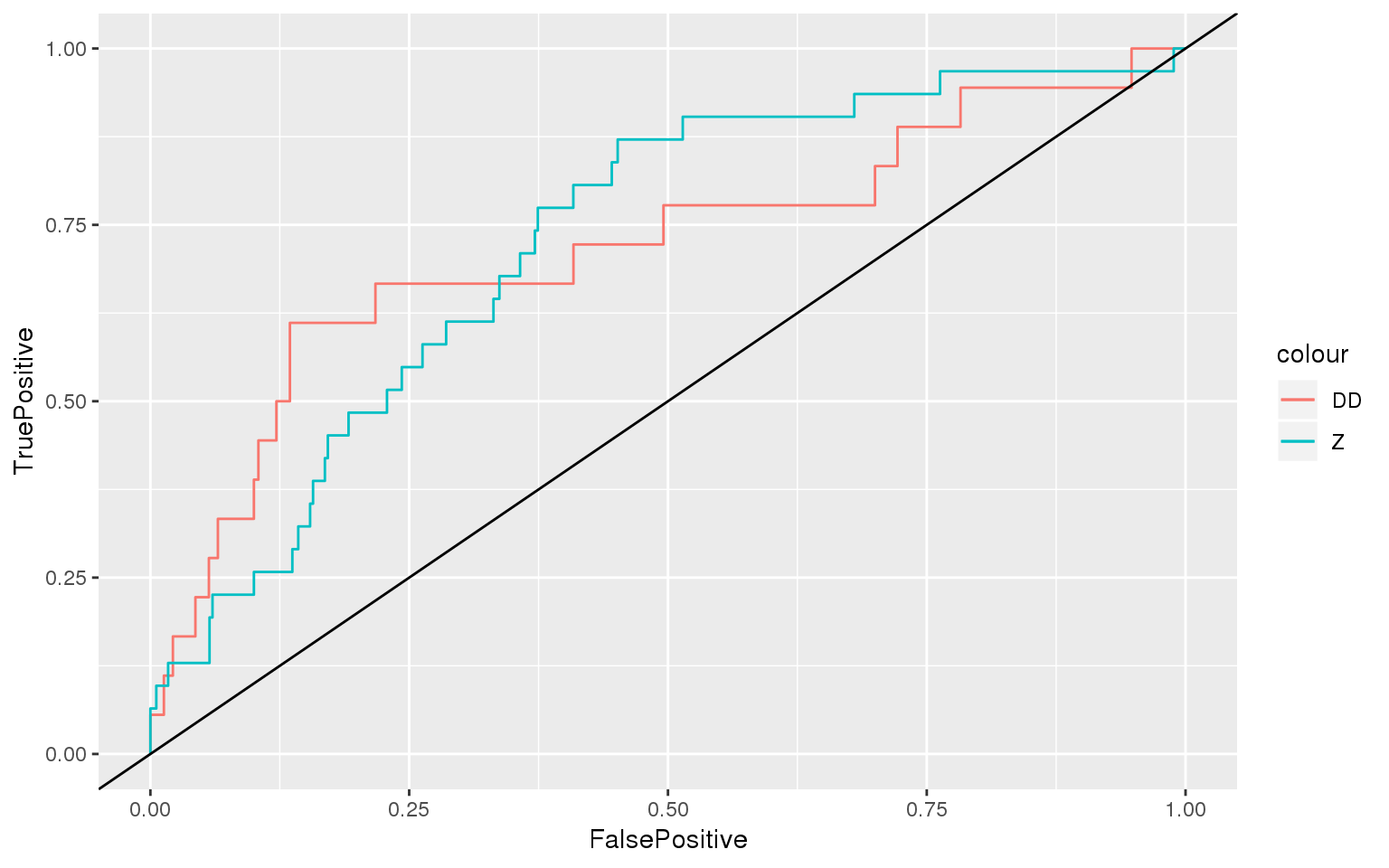
## Z DD
## 0.7270046 0.7183575