ACCT 420: ML/AI for visual data
Learning objectives

-
Theory:
- Neural Networks for…
- Images
- Audio
- Video
- Neural Networks for…
-
Application:
- Handwriting recognition
- Identifying financial information in images
-
Methodology:
- Neural networks
- CNNs
- Transformers
- Neural networks
Using images as data
- We can definitely use numeric matrices as data
- We did this plenty with XGBoost, for instance
- However, images have a lot of different numbers tied to each observation (image).

- Source: Twitter
- 798 rows
- 1200 columns
- 3 color channels
- 798 \(\times\) 1,200 \(\times\) 3 \(=\) 2,872,800
- The number of ‘variables’ per image like this!
Running the model
- It takes about 1 minute to run on an Nvidia GTX 1080

How CNNs work
- CNNs use repeated convolution, usually looking at slightly bigger chunks of data each iteration
- But what is convolution? It is illustrated by the following graphs (from Wikipedia):


CNN example: Alexnet
Example output of AlexNet

The first (of 5) layers learned

Recent attempts at explaining CNNs
- Google & Stanford’s “Automated Concept-based Explanation”

Try out a CNN in your browser!
-
Fashion MNIST with Keras and TPUs
- Fashion MNIST: A dataset of clothing pictures
- Keras: An easier API for TensorFlow
- TPU: A “Tensor Processing Unit” – A custom processor built by Google
- Python code

Examples: Financial




Examples: Non-financial



Running the model
- It takes about 10 minutes to run on an Nvidia GTX 1080
history <- model %>% fit_generator(
img_train, # training data
epochs = 10, # epoch
steps_per_epoch =
as.integer(train_samples/batch_size),
# print progress
verbose = 2,
)plot(history)
Optimizing the CNN
- The model we saw was run for 10 epochs (iterations)
- Why not more? Why not less?

How does Yolo do it? Map of Tiny YOLO

Yolo model and graphing tool from lutzroeder/netron
How does Yolo do it?
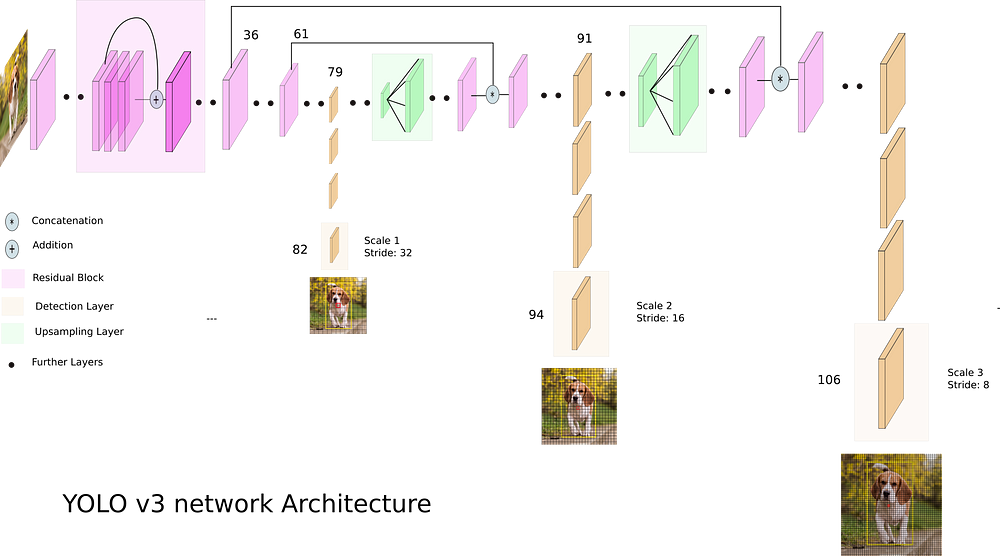
Diagram from What’s new in YOLO v3 by Ayoosh Kathuria
A word on ethics of object detection

From Redmon and Farhadi (2018) [The YOLO v3 paper]
CLIP
- Code for this is available at: rmc.link/colab_clip

Stable diffusion: Content
- Code to implement as a Telegram bot: rmcrowley2000/StableDiffBot
“A photo of the Singapore skyline including Marina Bay Sands”

“Singapore Management University”

Stable diffusion: Style
“Lithograph of a camel eating a pear”

“A cartoon icon of a dog getting a hair cut.”

Stable diffusion: Problems
“Sustainability data”

“A cavapoo enjoying a nice warm cup of tea”

Stable diffusion: Complexity
“Tiny cute isometric living room in a cutaway box, soft smooth lighting, soft colors, purple and blue color scheme, soft colors, 100mm lens, 3d blender render”

