# Run this in the R Console inside RStudio
install.packages(c("tidyverse","plotly"))ACCT 420: Linear Regression
Learning objectives

-
Theory:
- Develop a logical approach to problem solving with data
- Statistics
- Causation
- Hypothesis testing
- Develop a logical approach to problem solving with data
-
Application:
- Predicting revenue for real estate firms
-
Methodology:
- Univariate stats
- Linear regression
- Visualization
R Markdown: A quick guide
- Headers and subheaders start with
#and##, respectively - Code blocks starts with
```{r}and end with```- By default, all code and figures will show up in the document
- Inline code goes in a block starting with
`rand ending with` - Italic font can be used by putting
*or_around text - Bold font can be used by putting
**around text- E.g.:
**bold text**becomes bold text
- E.g.:
- To render the document, click

- Math can be placed between
$to use LaTeX notation- E.g.
$\frac{revt}{at}$becomes \(\frac{revt}{at}\)
- E.g.
- Full equations (on their own line) can be placed between
$$ - A block quote is prefixed with
> - For a complete guide, see the Quarto tutorials or Datacamp’s Quarto Cheat Sheet
The question
How can we predict revenue for a company, leveraging data about that company, related companies, and macro factors
- Specific application: Real estate companies

Photo courtesy of Wikimedia Commons
{kind=link}
Example
Let’s predict UOL’s revenue for 2016





- Compustat has data for them since 1989
- Complete since 1994
- Missing CapEx before that
- Complete since 1994
Why is it called Ordinary Least Squares?
library(tidyverse)
# uolg is defined in the class session code file
uolg %>% ggplot(aes(y=revt, x=at)) +
geom_point(aes(shape=point, group=point)) +
scale_shape_manual(values=c(NA,18)) +
geom_smooth(method="lm", se=FALSE) +
geom_errorbarh(aes(xmax=xright, xmin = xleft)) +
geom_errorbar(aes(ymax=ytop, ymin = ybottom)) +
theme(legend.position="none") + xlim(0, 20000) + ylim(0, 2500)
Mental model of OLS: 1 input

Simple OLS measures a simple linear relationship between 1 input and 1 output
- E.g.: Our first regression this week: Revenue on assets
Mental model of OLS: Multiple inputs
OLS measures simple linear relationships between a set of inputs and 1 output
- E.g.: This is what we did when scaling up earlier this session

Other linear models: IV Regression (2SLS)
IV/2SLS models linear relationships where the effect of some \(x_i\) on \(y\) may be confounded by outside factors.
- E.g.: Modeling the effect of management pay duration (like bond duration) on firms’ choice to issue earnings forecasts
- Instrument with CEO tenure (Cheng, Cho, and Kim 2015)

Other linear models: SUR
SUR models systems with related error terms
- E.g.: Modeling both revenue and earnings simultaneously

Other linear models: 3SLS
3SLS models systems of equations with related outputs
- E.g.: Modeling stock return, volatility, and volume simultaneously

Other linear models: SEM
SEM can model abstract and multi-level relationships
- E.g.: Showing that organizational commitment leads to higher job satisfaction, not the other way around (Poznanski and Bline 1999)

Modeling choices: Variable selection
- The options:
- Use your own knowledge to select variables
- Use a selection model to automate it
Own knowledge
- Build a model based on your knowledge of the problem and situation
- This is generally better
- The result should be more interpretable
- For prediction, you should know relationships better than most algorithms

Modeling choices: Automated selection
- Traditional methods include:
- Forward selection: Start with nothing and add variables with the most contribution to Adj \(R^2\) until it stops going up
- Backward selection: Start with all inputs and remove variables with the worst (negative) contribution to Adj \(R^2\) until it stops going up
- Stepwise selection: Like forward selection, but drops non-significant predictors
- Newer methods include:
- Lasso/Elastic Net based models
- Optimize with high penalties for complexity (i.e., # of inputs)
- These are proven to be better
- We will discuss these in week 6
- Lasso/Elastic Net based models

Coefficients
- In OLS: \(\beta_i\)
- A change in \(x_i\) by 1 leads to a change in \(y\) by \(\beta_i\)
- Essentially, the slope between \(x\) and \(y\)
- The blue line in the chart is the regression line for \(\hat{Revenue} = \alpha + \beta_i \hat{Assets}\) for all real estate firms globally, 1994-2021

One vs two tailed tests
- Best practice: Use a two tailed test with a p-value cutoff of 0.05 or 0.10
- 0.05 for easier problems, 0.10 for harder/noisier problems
- Second best practice: use a 1-tailed test with a p-value cutoff of 0.025 or 0.05 - This is mathematically equivalent to the best practice, but roundabout
- Common but generally inappropriate:
- Use a one tailed test with cutoffs of 0.05 or 0.10 because your hypothesis is directional

What is causality?
\(A \rightarrow B\)
- Causality is \(A\) causing \(B\)
- This means more than \(A\) and \(B\) are correlated
- I.e., If \(A\) changes, \(B\) changes. But \(B\) changing doesn’t mean \(A\) changed
- Unless \(B\) is 100% driven by \(A\)
- Very difficult to determine, particularly for events that happen [almost] simultaneously
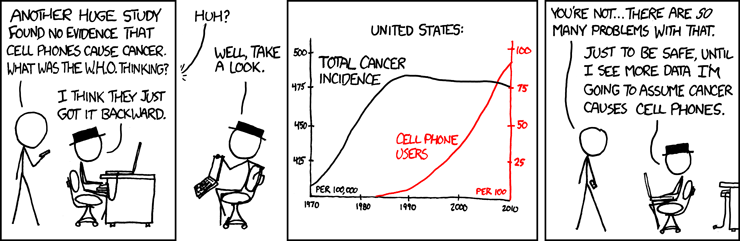
- Examples of correlations that aren’t causation

Time and causality break down
\[ A_t \rightarrow B_{t+1}? \quad \text{OR} \quad C \rightarrow A_t\text{ and }C \rightarrow B_{t+1}? \]
- The above illustrates the Correlated omitted variable problem
- \(A\) doesn’t cause \(B\)… Instead, some other force \(C\) causes both
- This is the bane of social scientists everywhere
- It is less important for predictive analytics, as we care more about performance, but…
- It can complicate interpreting your results
- Figuring out \(C\) can help improve you model’s predictions (So find C!)
All Singapore real estate companies

Macro data sources
- For Singapore: Data.gov.sg
- Covers: Economy, education, environment, finance, health, infrastructure, society, technology, transport
- For real estate in Singapore: URA’s REALIS system
- Access through the library
- WRDS has some as well
- For US: data.gov, as well as many agency websites
- Like BLS or the Federal Reserve



Panel data

Data frames are usually wide panels
Scaling matters
- All of our firm data is on the same terms as revenue: dollars within a given firm
- But
fin_sentimentis a constant scale…- We need to scale this to fit the problem
- The current scale would work for revenue growth
- We need to scale this to fit the problem
df_SG_macro %>%
ggplot(aes(y=revt_lead,
x=fin_sentiment)) +
geom_point()
df_SG_macro %>%
ggplot(aes(y=revt_lead,
x=fin_sentiment * revt)) +
geom_point()
Custom code
# Graph showing squared error (slide 4.6)
uolg <- uol[,c("at","revt")]
uolg$resid <- mod1$residuals
uolg$xleft <- ifelse(uolg$resid < 0,uolg$at,uolg$at - uolg$resid)
uolg$xright <- ifelse(uolg$resid < 0,uolg$at - uolg$resid, uol$at)
uolg$ytop <- ifelse(uolg$resid < 0,uolg$revt - uolg$resid,uol$revt)
uolg$ybottom <- ifelse(uolg$resid < 0,uolg$revt, uolg$revt - uolg$resid)
uolg$point <- TRUE
uolg2 <- uolg
uolg2$point <- FALSE
uolg2$at <- ifelse(uolg$resid < 0,uolg2$xright,uolg2$xleft)
uolg2$revt <- ifelse(uolg$resid < 0,uolg2$ytop,uolg2$ybottom)
uolg <- rbind(uolg, uolg2)
uolg %>% ggplot(aes(y=revt, x=at, group=point)) +
geom_point(aes(shape=point)) +
scale_shape_manual(values=c(NA,18)) +
geom_smooth(method="lm", se=FALSE) +
geom_errorbarh(aes(xmax=xright, xmin = xleft)) +
geom_errorbar(aes(ymax=ytop, ymin = ybottom)) +
theme(legend.position="none")# Chart of mean revt_lead for Singaporean firms (slide 12.6)
df_clean %>% # Our data frame
filter(fic=="SGP") %>% # Select only Singaporean firms
group_by(isin) %>% # Group by firm
mutate(mean_revt_lead=mean(revt_lead, na.rm=T)) %>% # Determine each firm's mean revenue (lead)
slice(1) %>% # Take only the first observation for each group
ungroup() %>% # Ungroup (we don't need groups any more)
ggplot(aes(x=mean_revt_lead)) + # Initialize plot and select data
geom_histogram(aes(y = ..density..)) + # Plots the histogram as a density so that geom_density is visible
geom_density(alpha=.4, fill="#FF6666") # Plots smoothed density ![]()