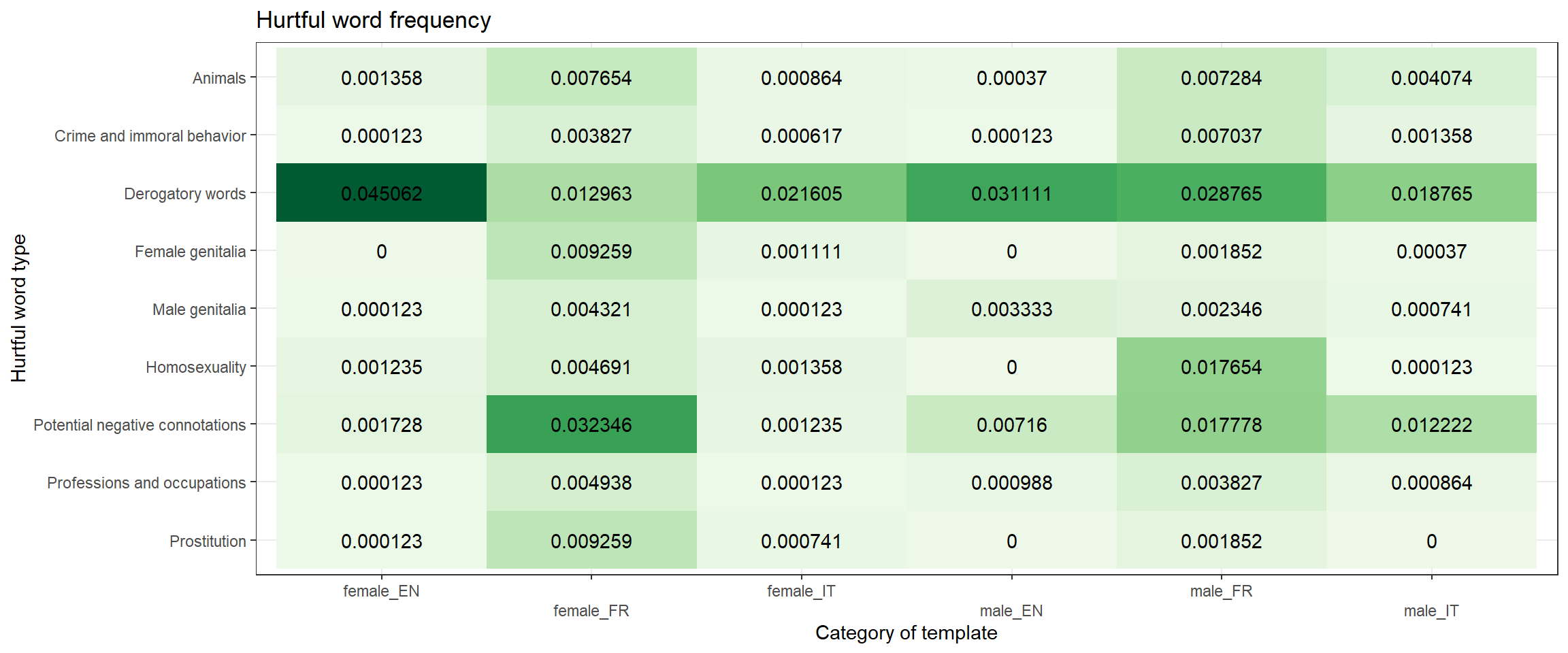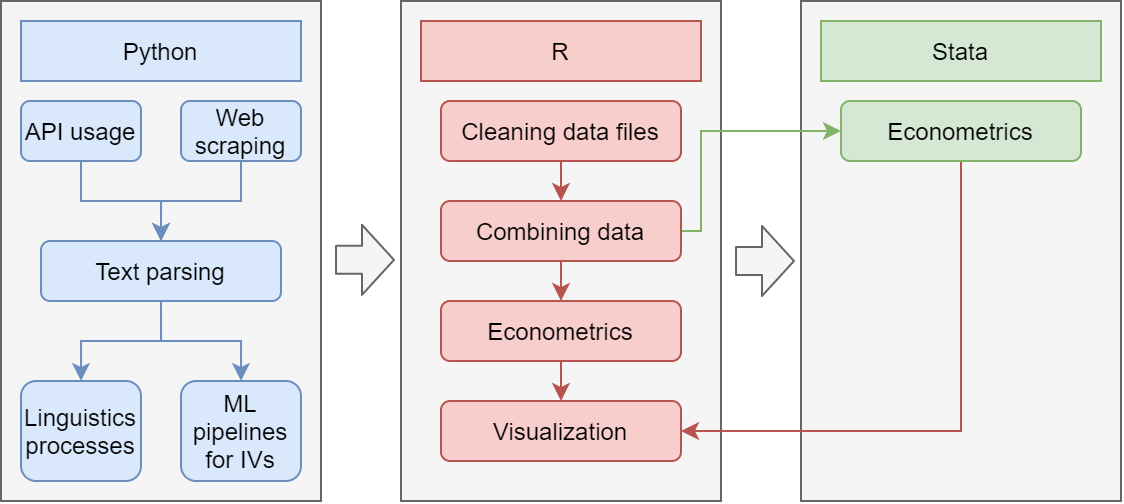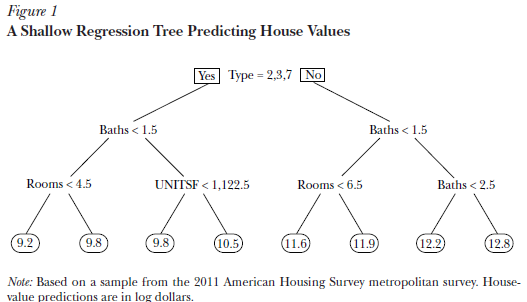
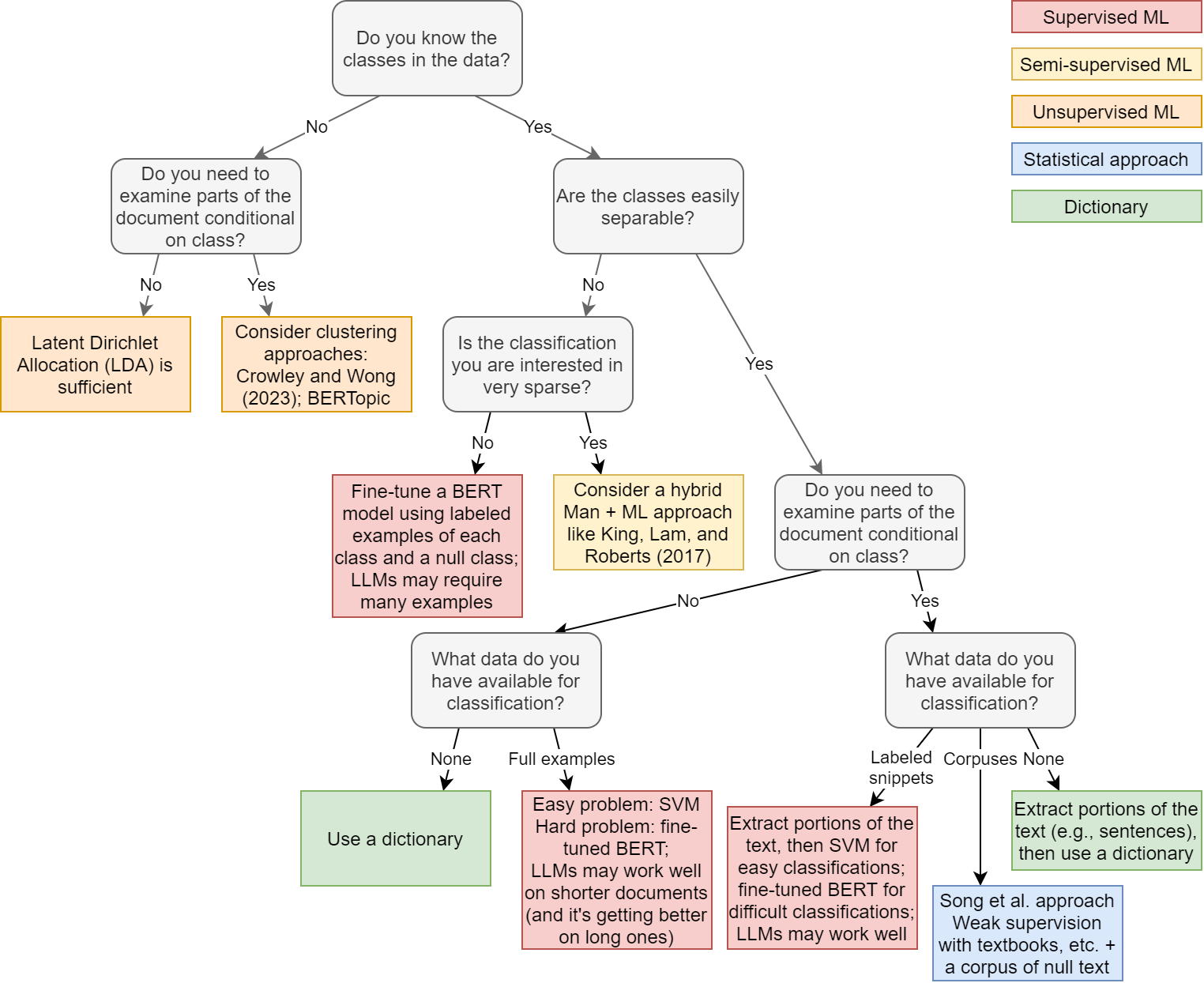

| words | f_animal | f_people | f_location |
|---|---|---|---|
| dog | 0.5 | 0.3 | -0.3 |
| cat | 0.5 | 0.1 | -0.3 |
| Bill | 0.1 | 0.9 | -0.4 |
| turkey | 0.5 | -0.2 | -0.3 |
| Turkey | -0.5 | 0.1 | 0.7 |
| Singapore | -0.5 | 0.1 | 0.8 |
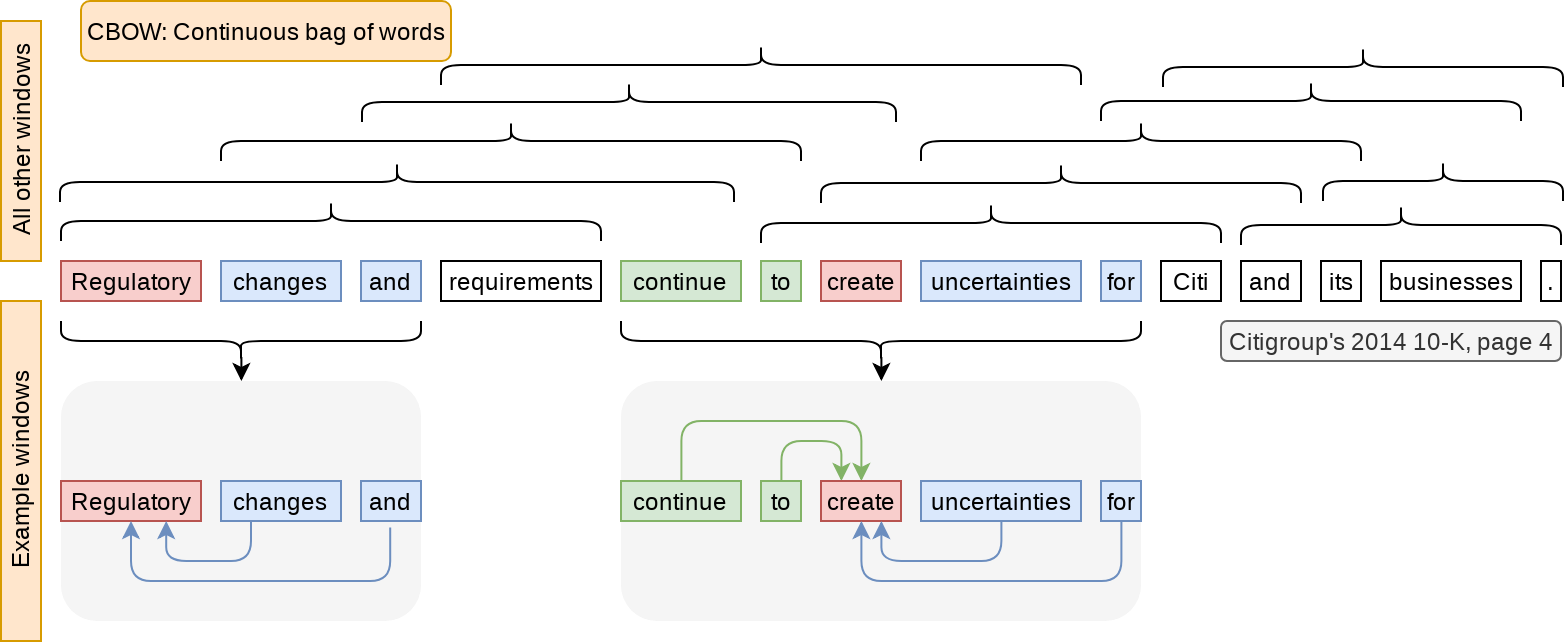
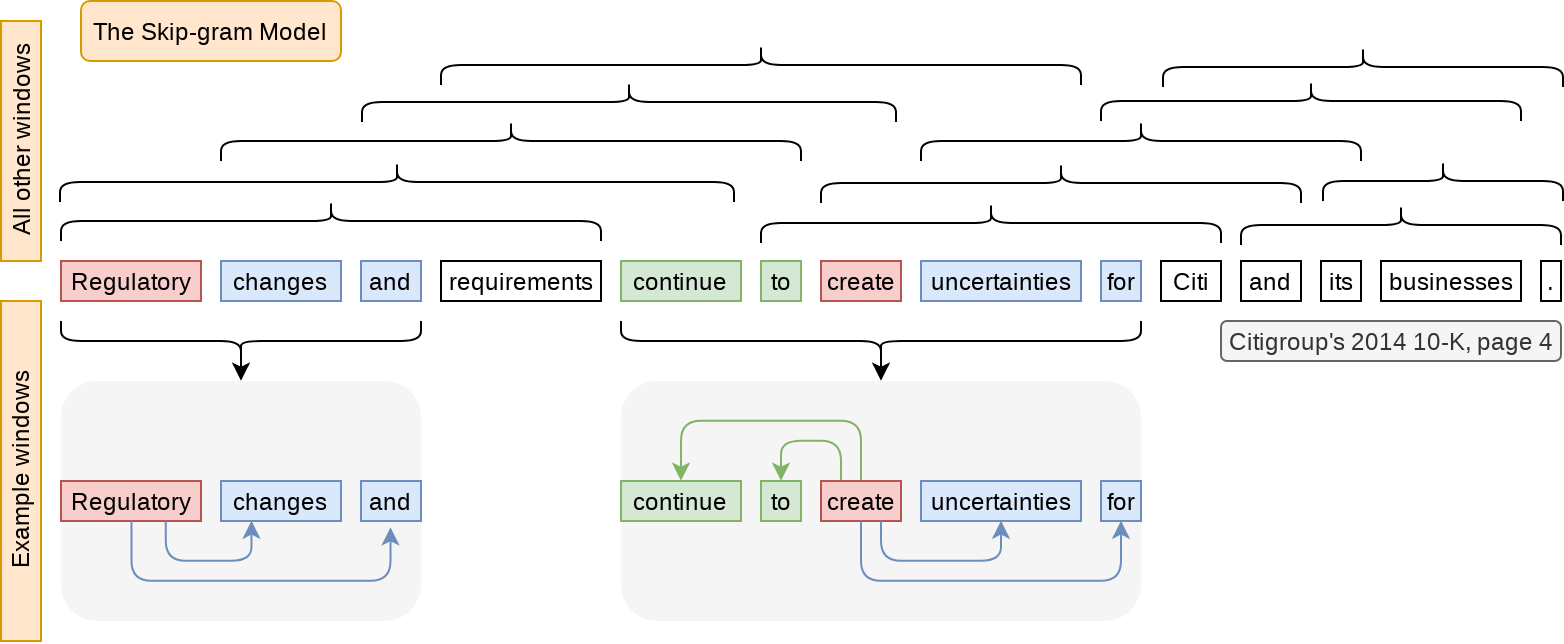
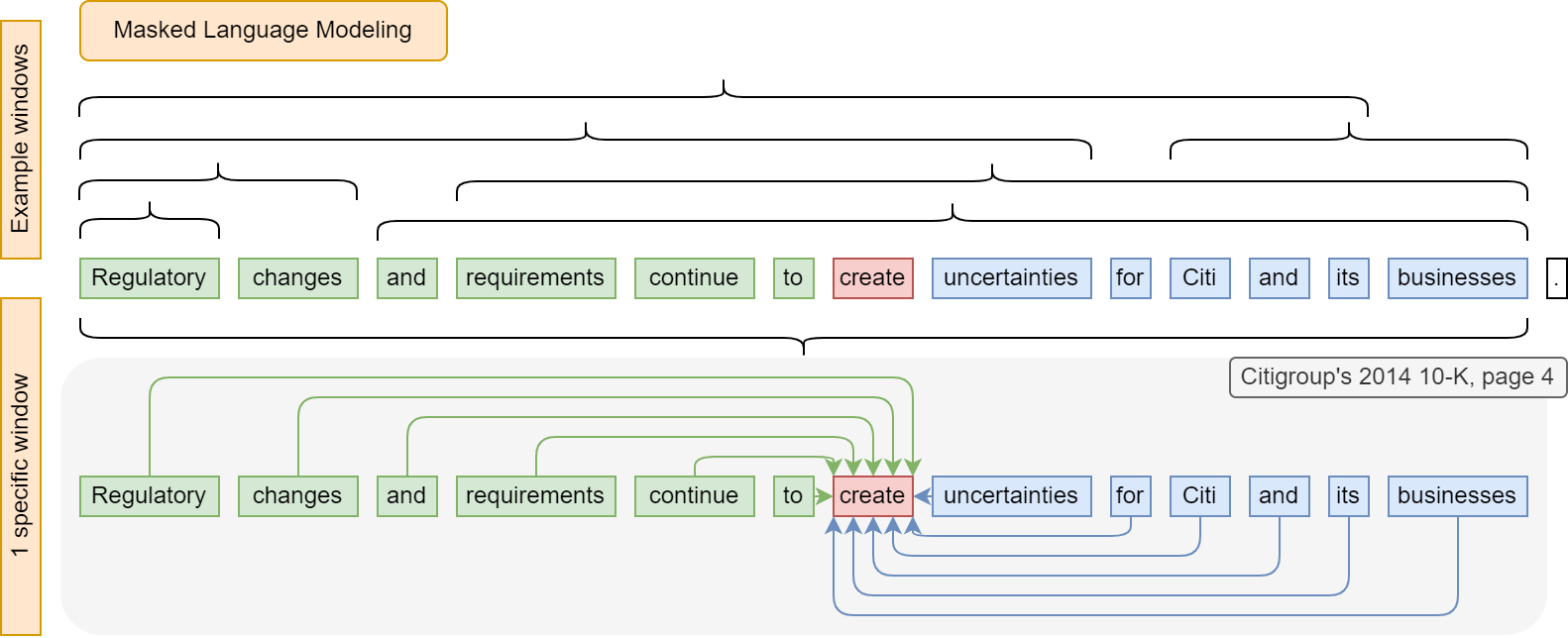
Main loop
The core function is the following:
text = row['template_masked']
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": "Responding with 1 word, fill in the next word of the sentence: " + text.replace('[M]','')
}
],
n=10
)For this test, we iterate over templates and template languages