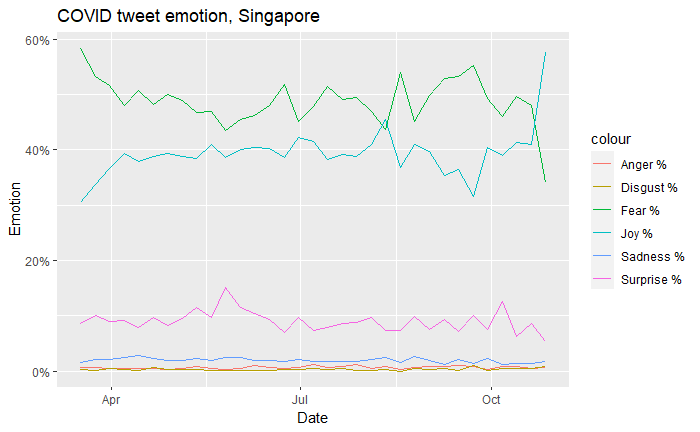What does Twitter provide?
The text of the message
- Enrichments through pictures, video, polls, links, hashtags, cashtags, and user mentions
- Language categorization
- Is it a quote or retweet?
- Number of likes
- Number of retweets
User information
- A unique ID + their chosen username
- Profile picture
- Self reported description and URL
- Self-reported user location
- Verification status
- Followers
- Following

Raw data vs what you see
{
"truncated": false,
"text": "GS reports 2014 net rev of $34.53bn, net earnings of $8.48bn, & 11.2% ROE; 4Q net rev of $7.69bn, net earnings of $2.17bn and 11.1% ROE",
"is_quote_status": false,
"id": 556067748196139008,
"favorite_count": 11,
"source": "<a href=\"http://www.spredfast.com\" rel=\"nofollow\">Spredfast app</a>",
"retweeted": false,
"entities": {
"symbols": [],
"user_mentions": [],
"hashtags": [],
"urls": []
},
"retweet_count": 31,
"id_str": "556067748196139008",
"favorited": false,
"user": {
"follow_request_sent": false,
"has_extended_profile": false,
"profile_use_background_image": true,
"default_profile_image": false,
"id": 253167239,
"profile_background_image_url_https": "https://pbs.twimg.com/profile_background_images/378800000018727168/b1841e59295b5a69abc238a705e3b030.jpeg",
"verified": true,
"translator_type": "none",
"profile_text_color": "333333",
"profile_image_url_https": "https://pbs.twimg.com/profile_images/465954359583322112/mvHVOgH8_normal.jpeg",
"profile_sidebar_fill_color": "DDEEF6",
"entities": {
"url": {
"urls": [
{
"url": "http://t.co/IORXQSIgTV",
"indices": [
0,
22
],
"expanded_url": "http://www.goldmansachs.com",
"display_url": "goldmansachs.com"
}
]
},
"description": {
"urls": []
}
},
"followers_count": 604559,
"profile_sidebar_border_color": "FFFFFF",
"id_str": "253167239",
"profile_background_color": "7399C6",
"listed_count": 4986,
"is_translation_enabled": false,
"utc_offset": -14400,
"statuses_count": 7527,
"description": "Official Goldman Sachs Twitter account. Follow us for the latest in global and local economic progress, firm news, and thought leadership content.",
"friends_count": 104,
"location": "",
"profile_link_color": "7399C6",
"profile_image_url": "http://pbs.twimg.com/profile_images/465954359583322112/mvHVOgH8_normal.jpeg",
"following": false,
"geo_enabled": false,
"profile_banner_url": "https://pbs.twimg.com/profile_banners/253167239/1440625536",
"profile_background_image_url": "http://pbs.twimg.com/profile_background_images/378800000018727168/b1841e59295b5a69abc238a705e3b030.jpeg",
"screen_name": "GoldmanSachs",
"lang": "en",
"profile_background_tile": false,
"favourites_count": 5,
"name": "Goldman Sachs",
"notifications": false,
"url": "http://t.co/IORXQSIgTV",
"created_at": "Wed Feb 16 17:59:09 +0000 2011",
"contributors_enabled": false,
"time_zone": "Eastern Time (US & Canada)",
"protected": false,
"default_profile": false,
"is_translator": false
},
"lang": "en",
"created_at": "Fri Jan 16 12:37:37 +0000 2015"
}
How can we classify general text?
- Latent Dirichlet Allocation (LDA)
- One of the most popular methods under the field of topic modeling
- LDA is a Bayesian method of assessing the content of a document
- LDA assumes there are a set of topics in each document, and that this set follows a Dirichlet prior for each document
- Words within topics also have a Dirichlet prior

What about for Twitter posts?
- Leverages assumptions about word co-occurence (as in LDA)
- Adds in user information to examine word usage across users
The question
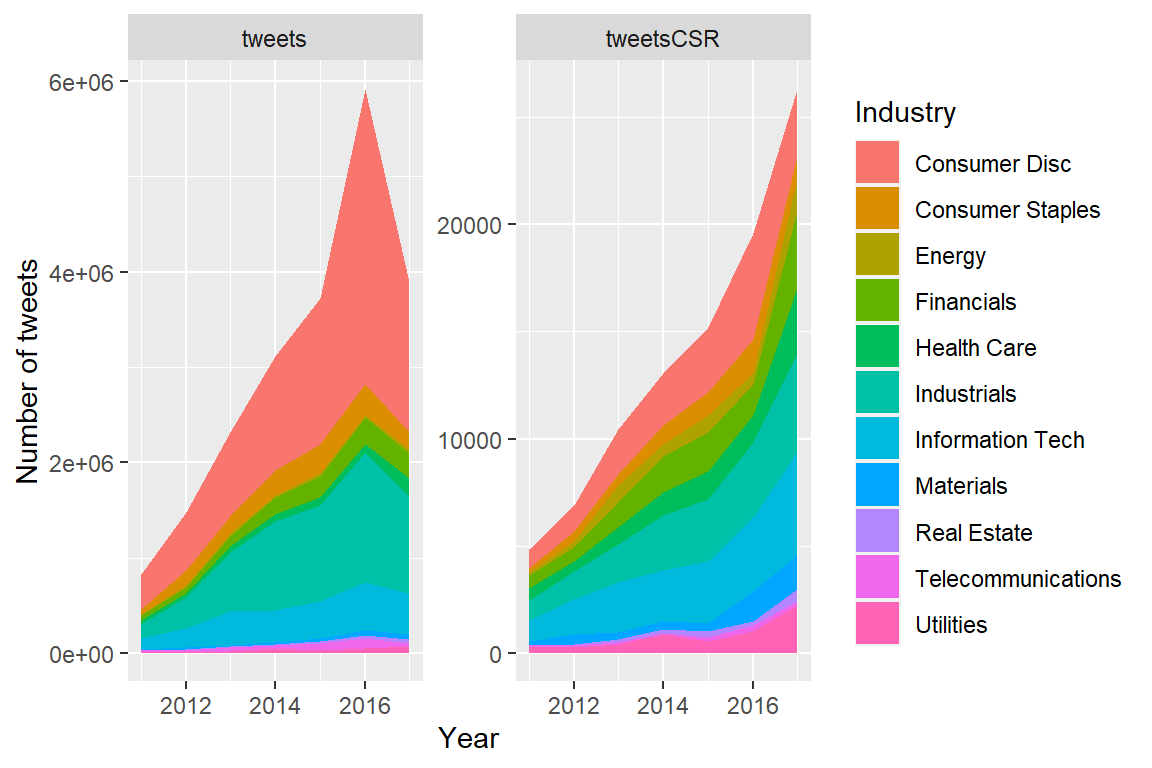
Question: Are firms using Twitter to greenwash?
Disseminating actual CSR activities
Greenwashing 
Implementation: Is the # of CSR tweets negatively associated with firms’ CSR scores?
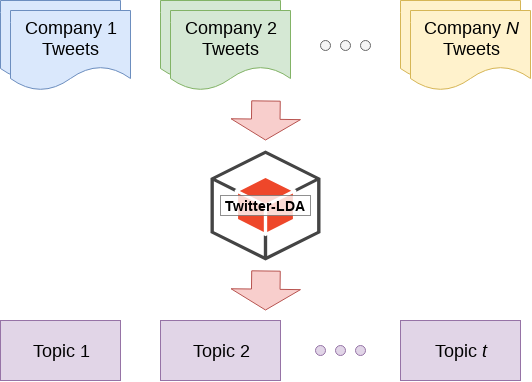
Machine learning classification
- Classify using Twitter-LDA
- See reference papers for usage
- Identify 100 topics
- Find 2 topics related to CSR
- Sustainability and natural resources
- Community service
- Find 1 topic related to financial information
- 97 other topics
- Much of it related to marketing and customer service
- Find 2 topics related to CSR
Results
\[ CSRtweets = \alpha + \beta_1 Lag(CSR) + \gamma Controls + \varepsilon \]
- Expect:
- \(\beta_1 > 0\) if good corporate citizens
- \(\beta_1 < 0\) if greenwashing

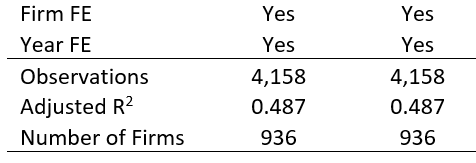
- Results support the greenwashing story
Measuring content similarity
Difficulty: Tweets are short, so word choice isn’t a reliable measure
Solution
- Universal sentence encoder (USE, Cer et al. 2018)
- Determines meaning of text based on all words in the text
- A measure of meaning, not word choice
- Neural network based (Deep Averaging Network)
How does USE work?
- Input: words and bigrams mapped to embeddings
- Processing: Averaging + a 4-layer neural network (called a Deep Averaging Network)
- Output: A sentence embedding of 512 dimensions
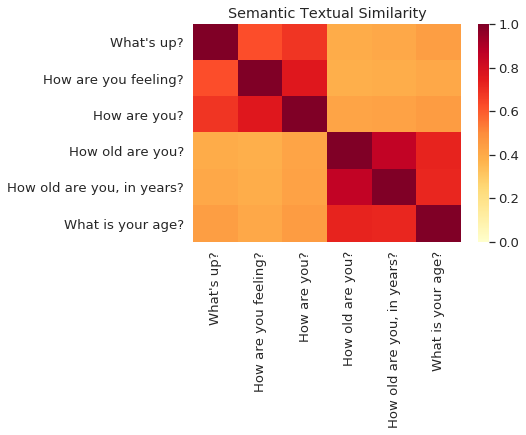
USE abstracts away from word choice!
Stock reaction mechanism

- Main effect of executive tweets is subsumed
- Effect comes from executive tweets that are similar to firm tweets
- This effect seems to encourage reaction to firm tweets as well
Consistent with effect coming from trust; inconsistent with an information story
- Robust to other definitions of the similarity measure
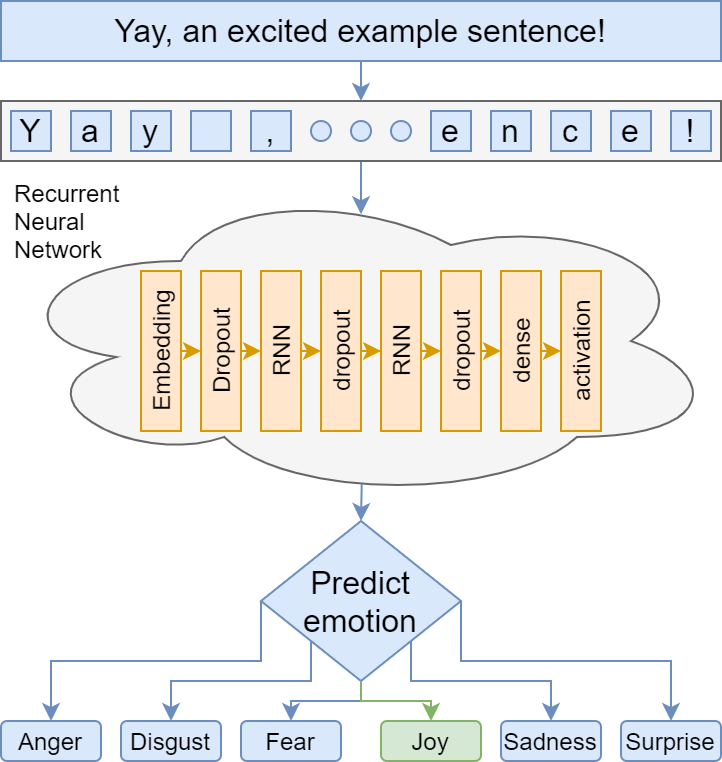
Measuring Emotion
Done using Twitter Emotion Recognition from Colneric and Demsar (2020)
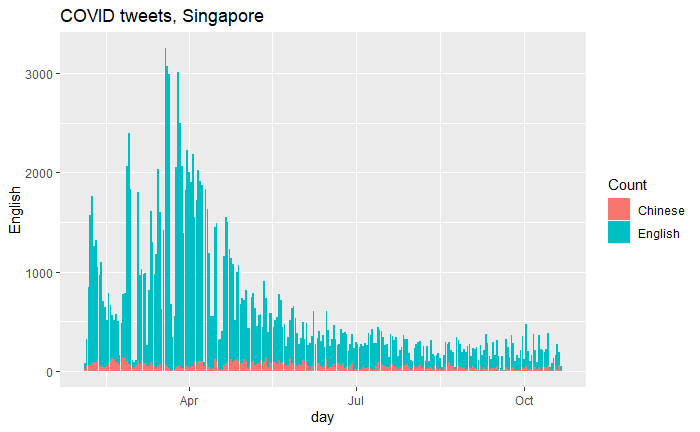
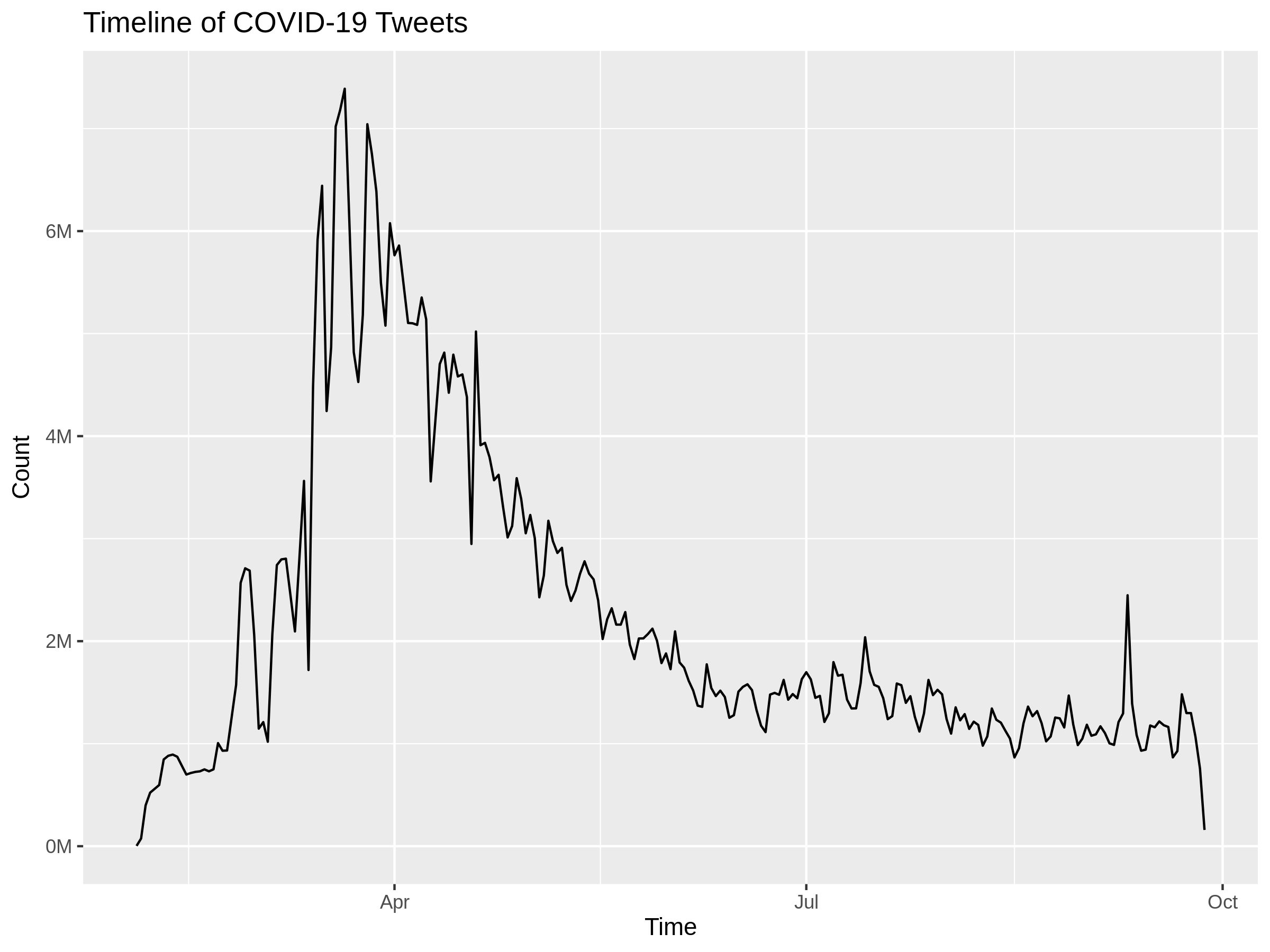
Timing of the data
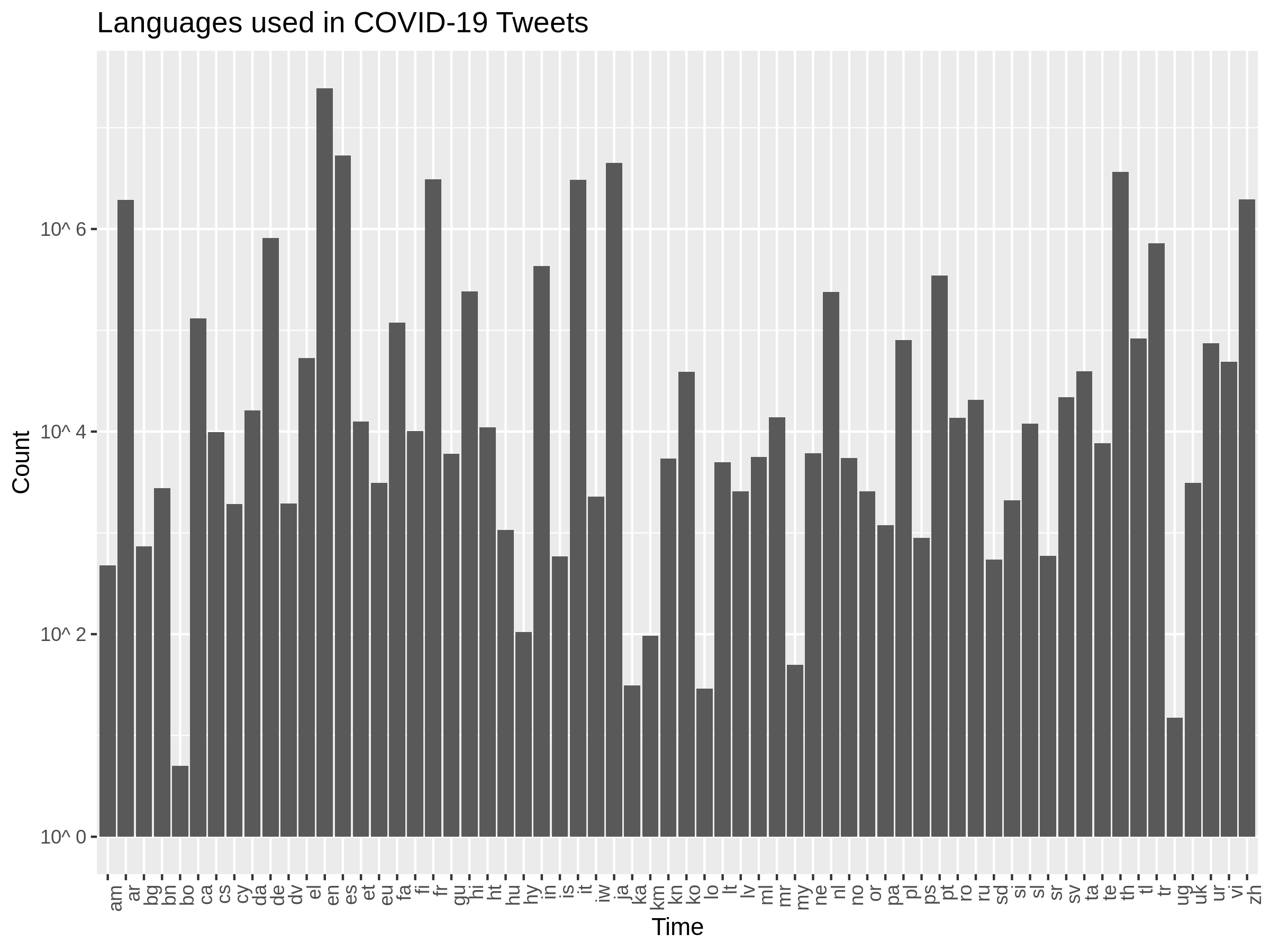
Data by language
Language usage in the US
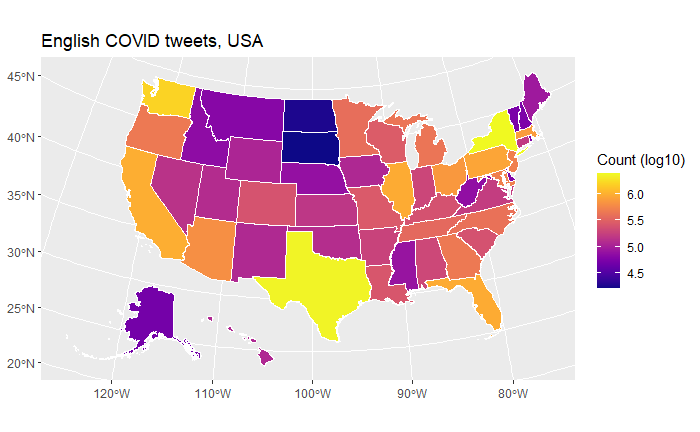
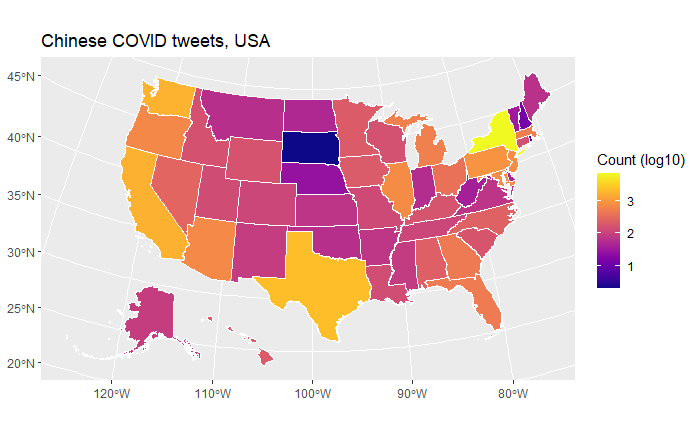
Singapore