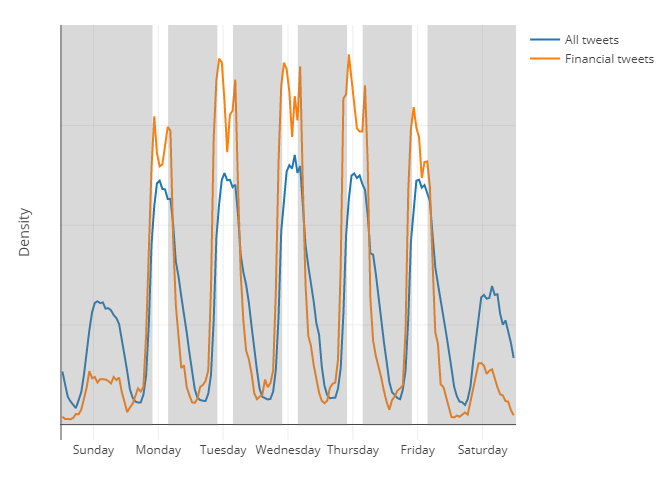
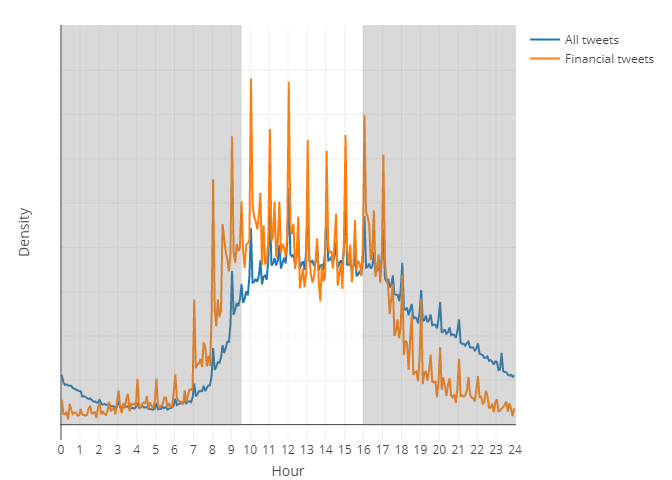
>28 million tweets
Greenwashing
How can we detect if a firm is currently involved in a major instance of misreporting?
Why do we care?
Catching even 1 more of these as they happen could save billions of dollars
Errors that affect firms’ accounting statements or disclosures which were done seemingly intentionally by management or other employees at the firm.
Fraud happens in many ways, for many reasons
It is disclosed in many places. All have subtly different meanings and implications
This is a hard problem!
Why do we do this? — Think like a fraudster!
To learn more: More advanced slides for the fraud detection work are available at rmc.link/DSSG Technical details publicly available at SSRN for both papers Plenty more information on my website at rmc.link
To learn more:
Instrument: A word intrusion task
Participants
These learn the “meaning” of words in a given context
Run the exact same experiment as on humans
Based on Dechow, Ge, Larson and Sloan (2011)
From a variety of research papers