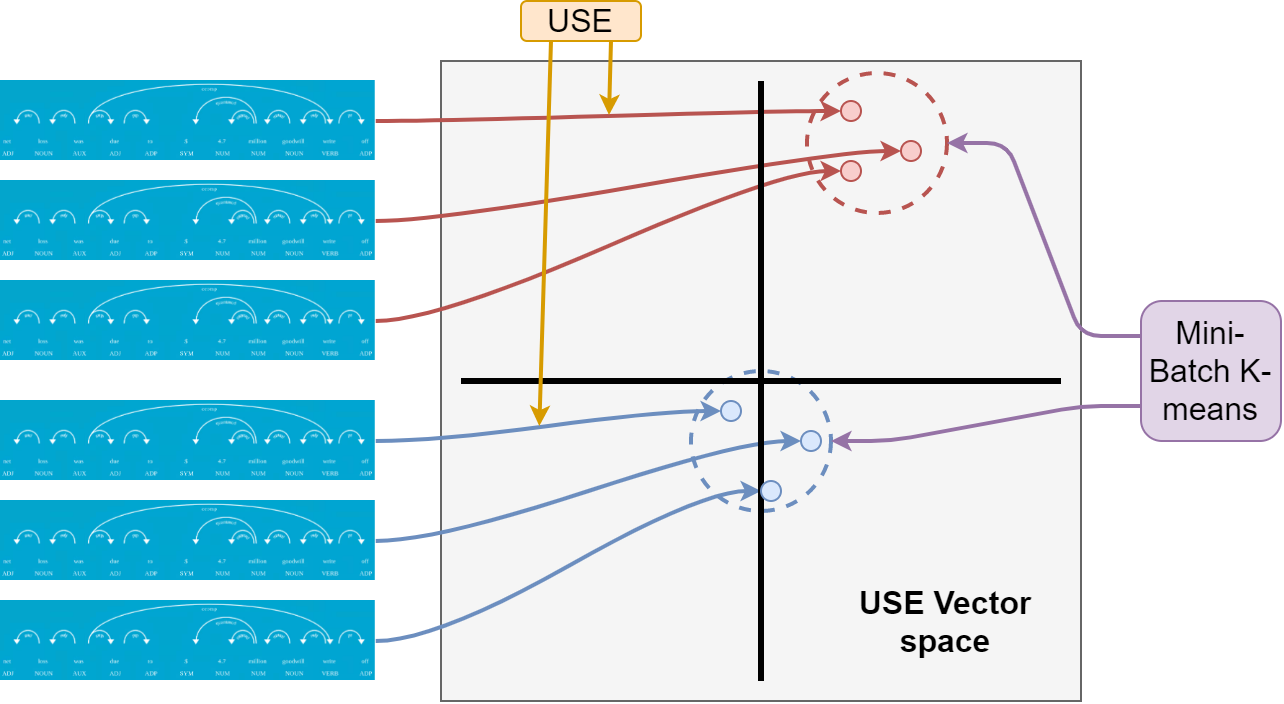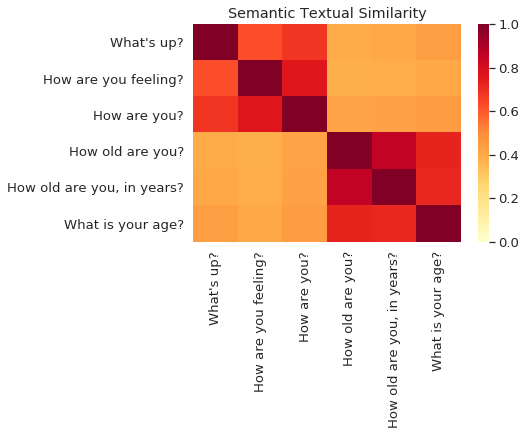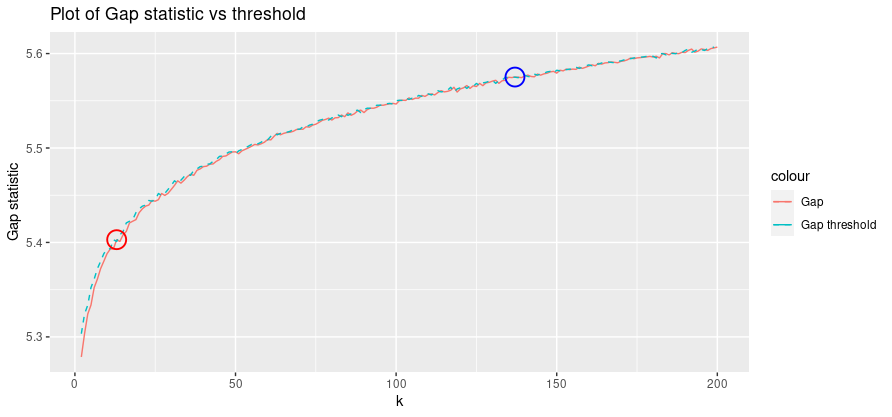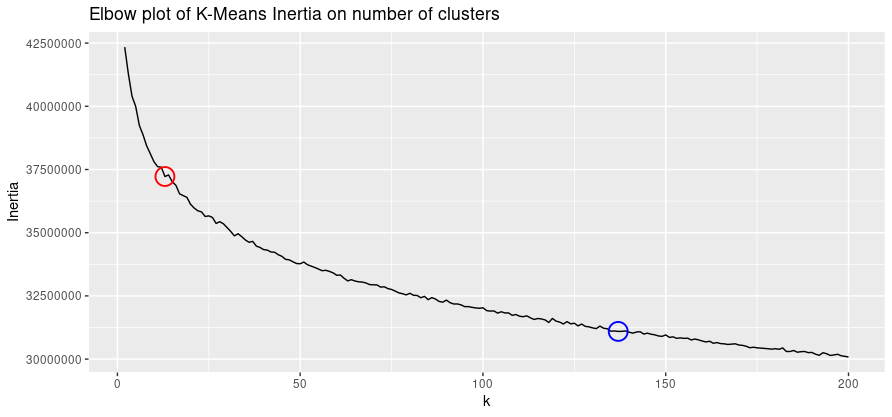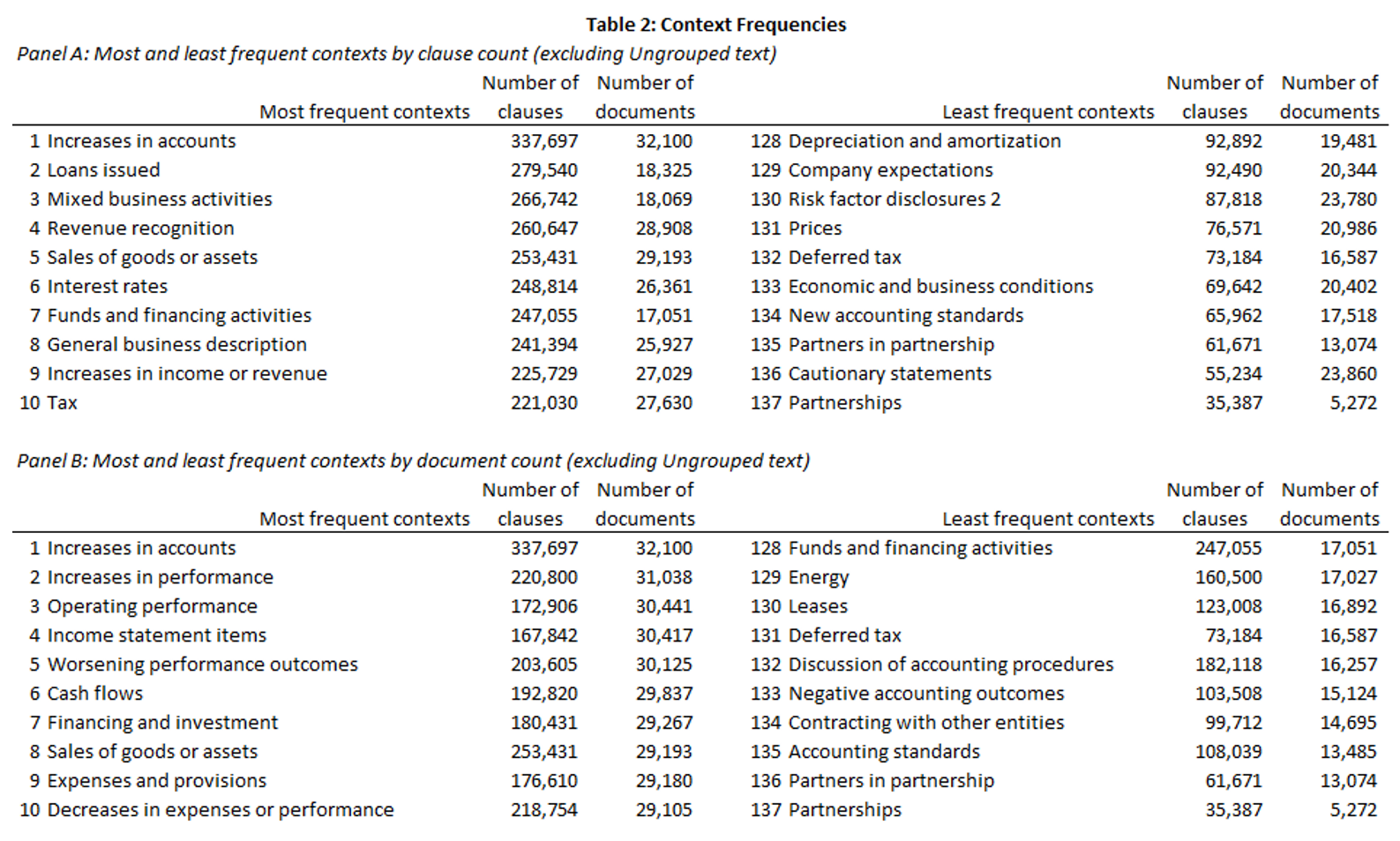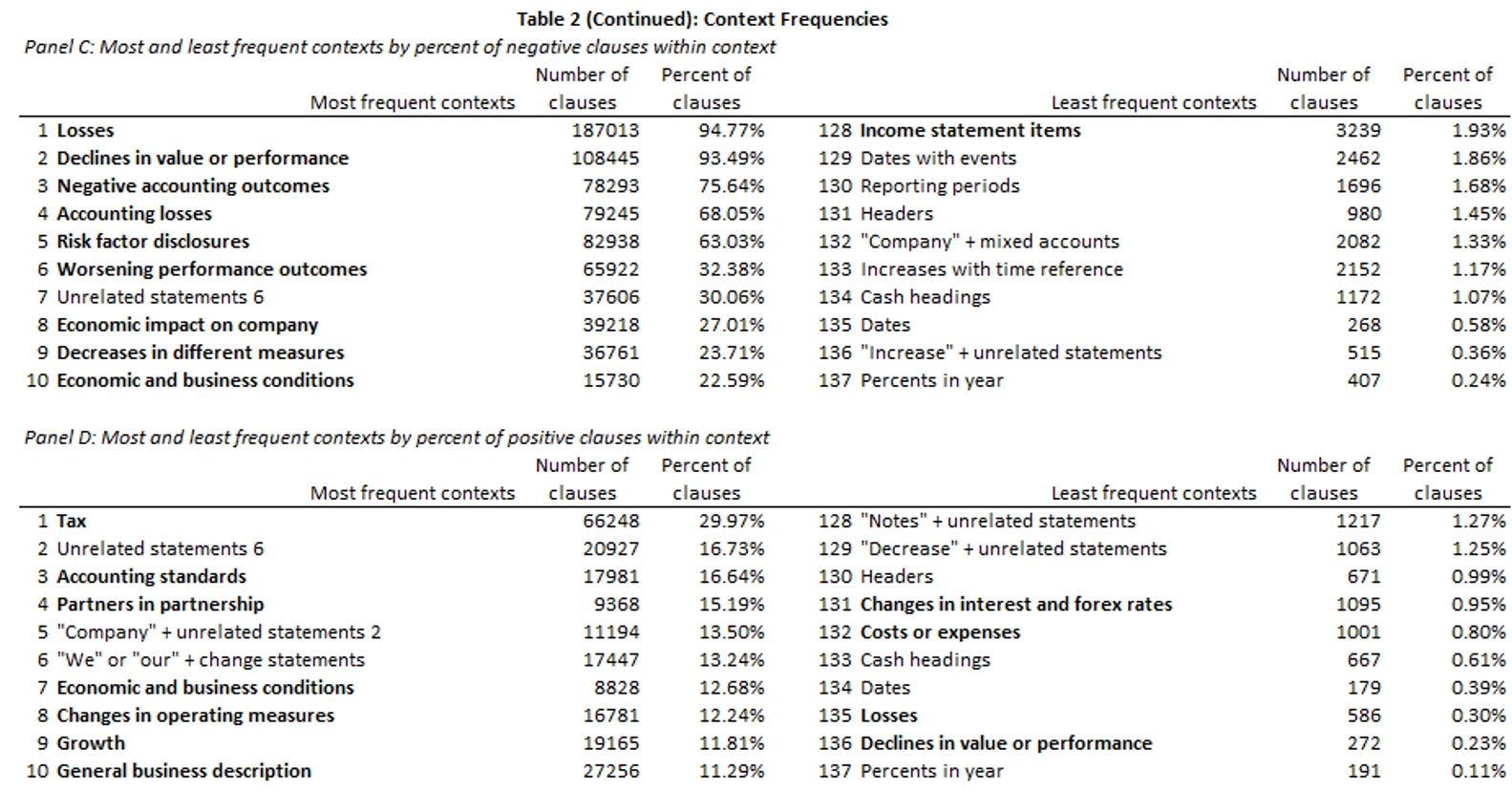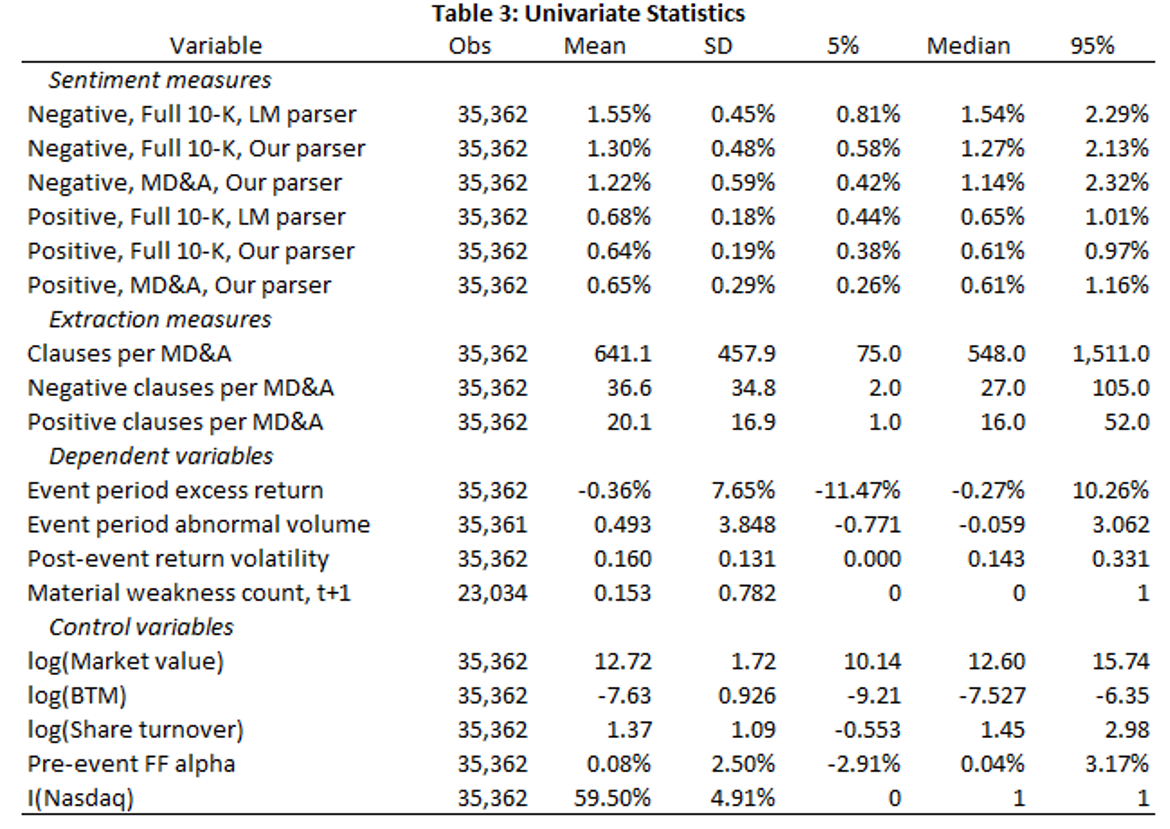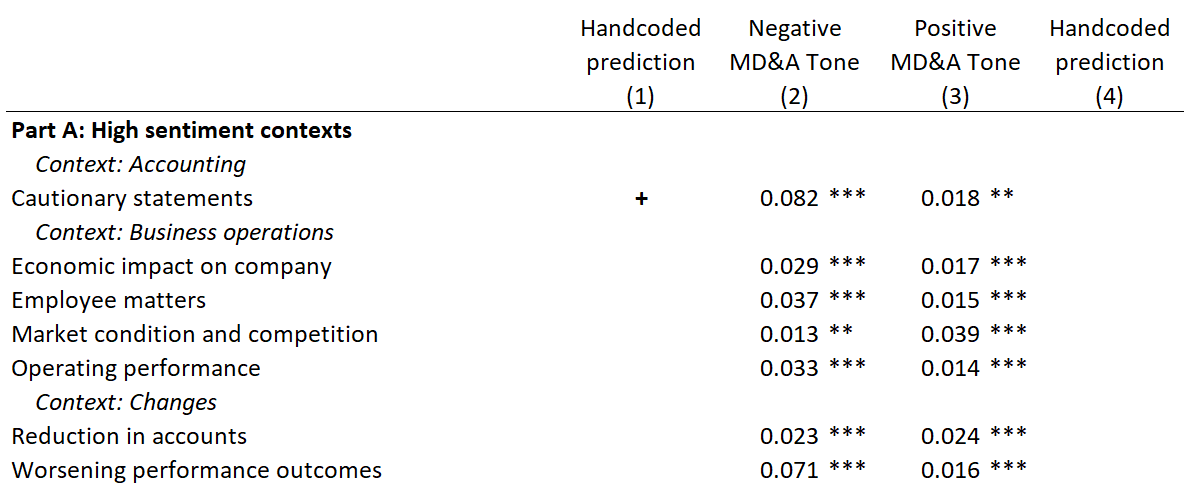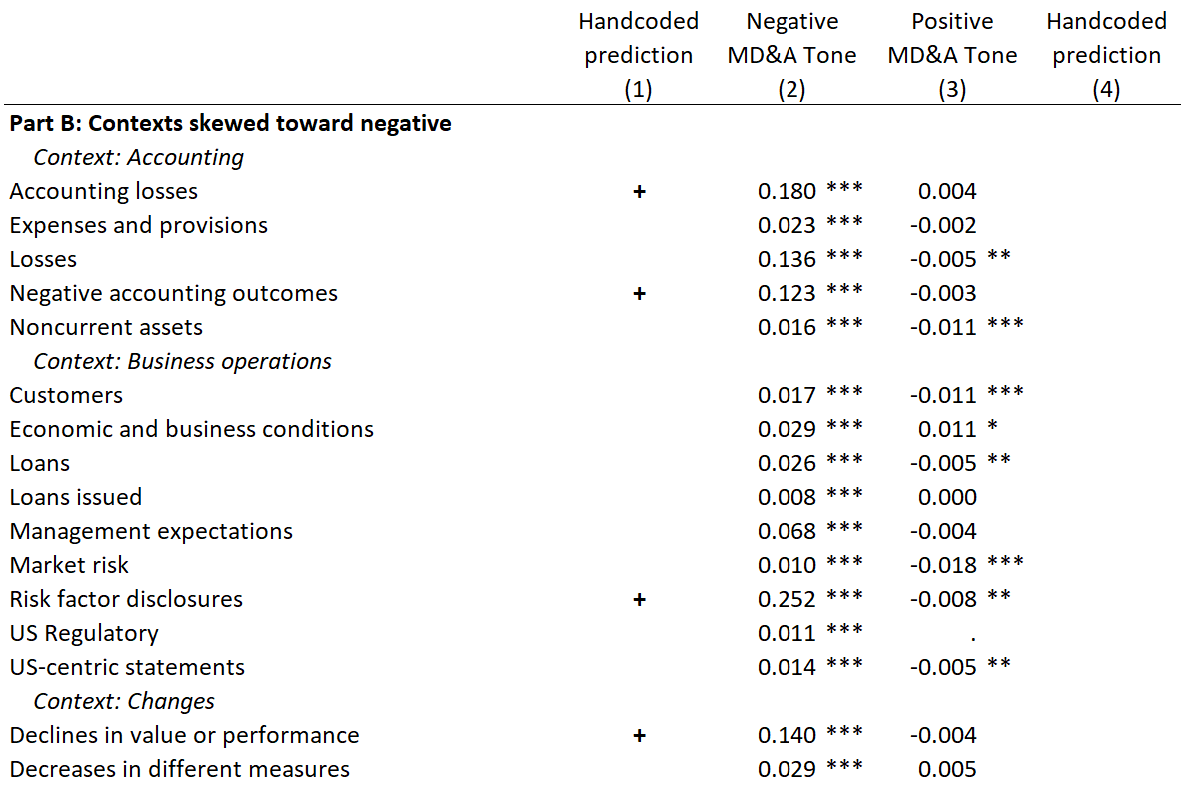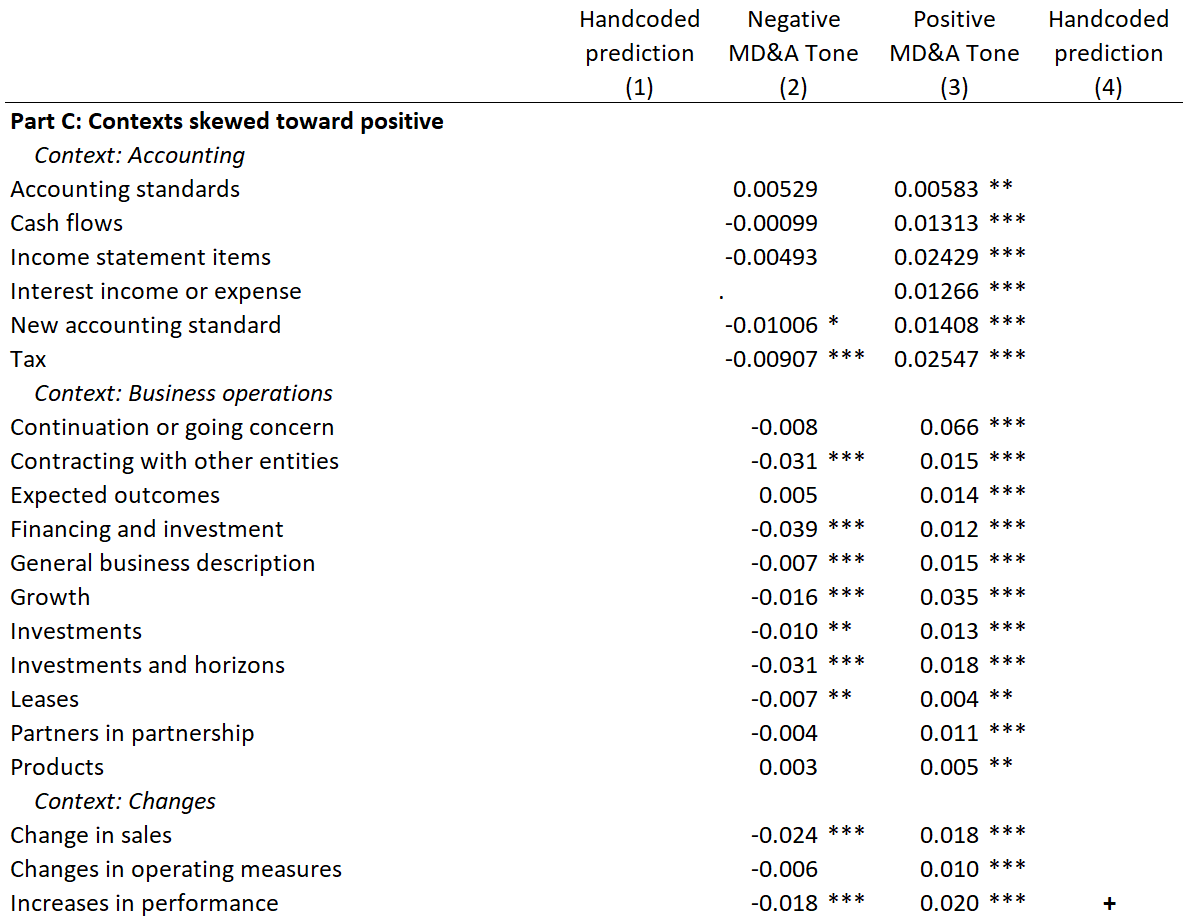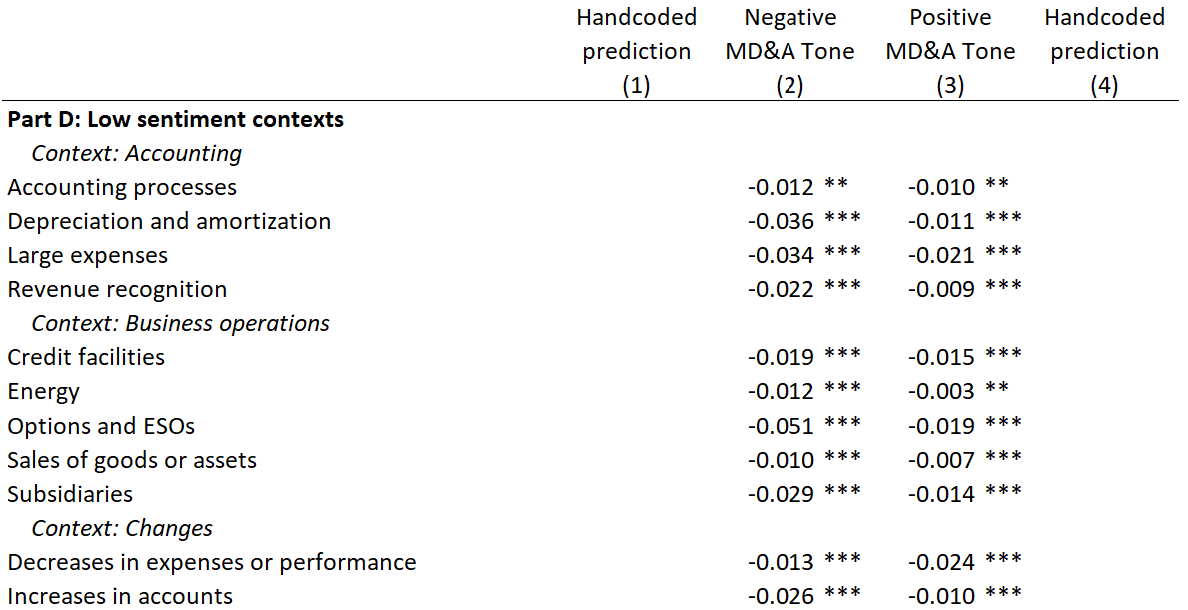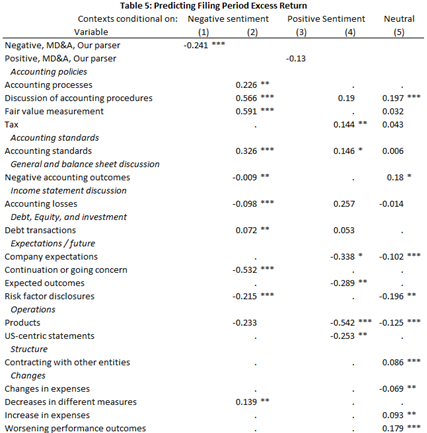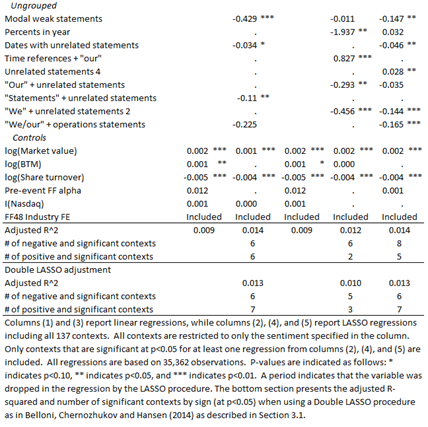

Main results
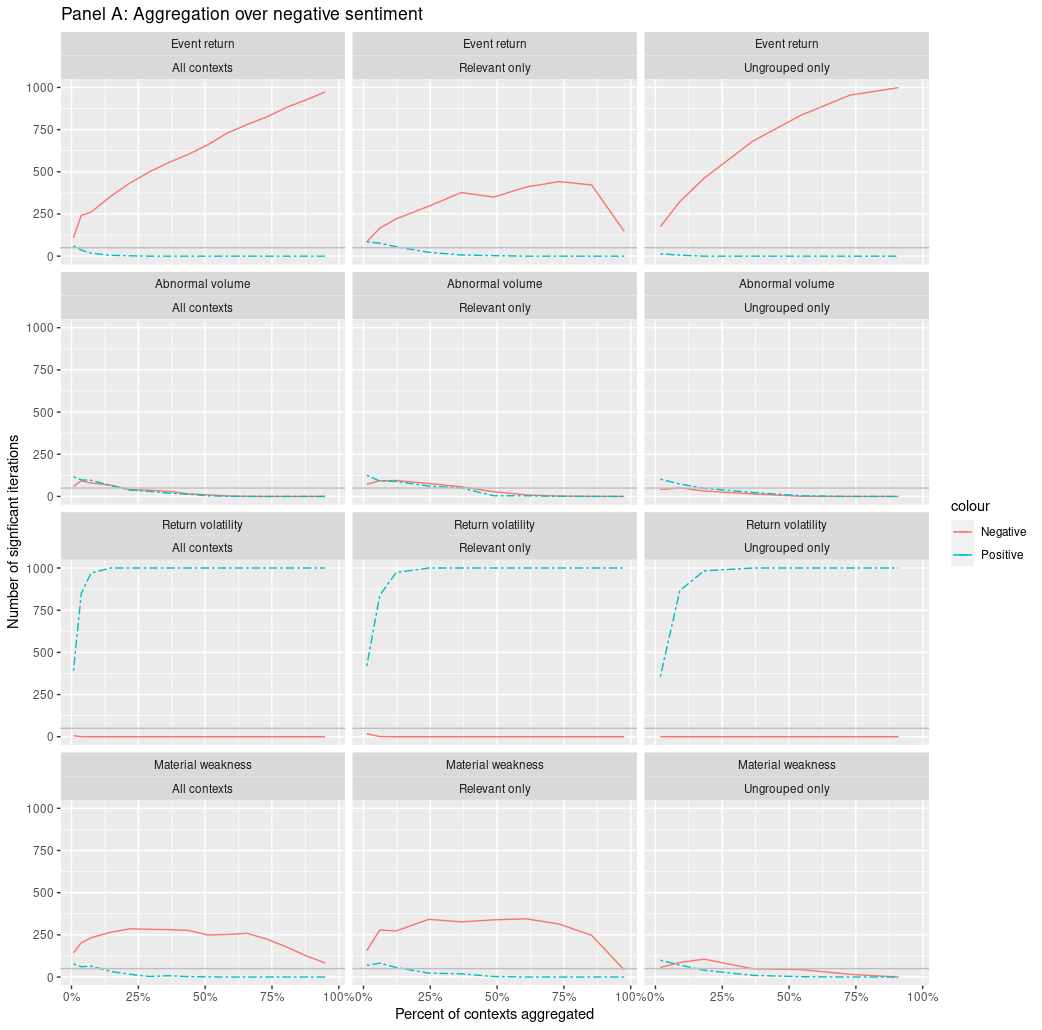
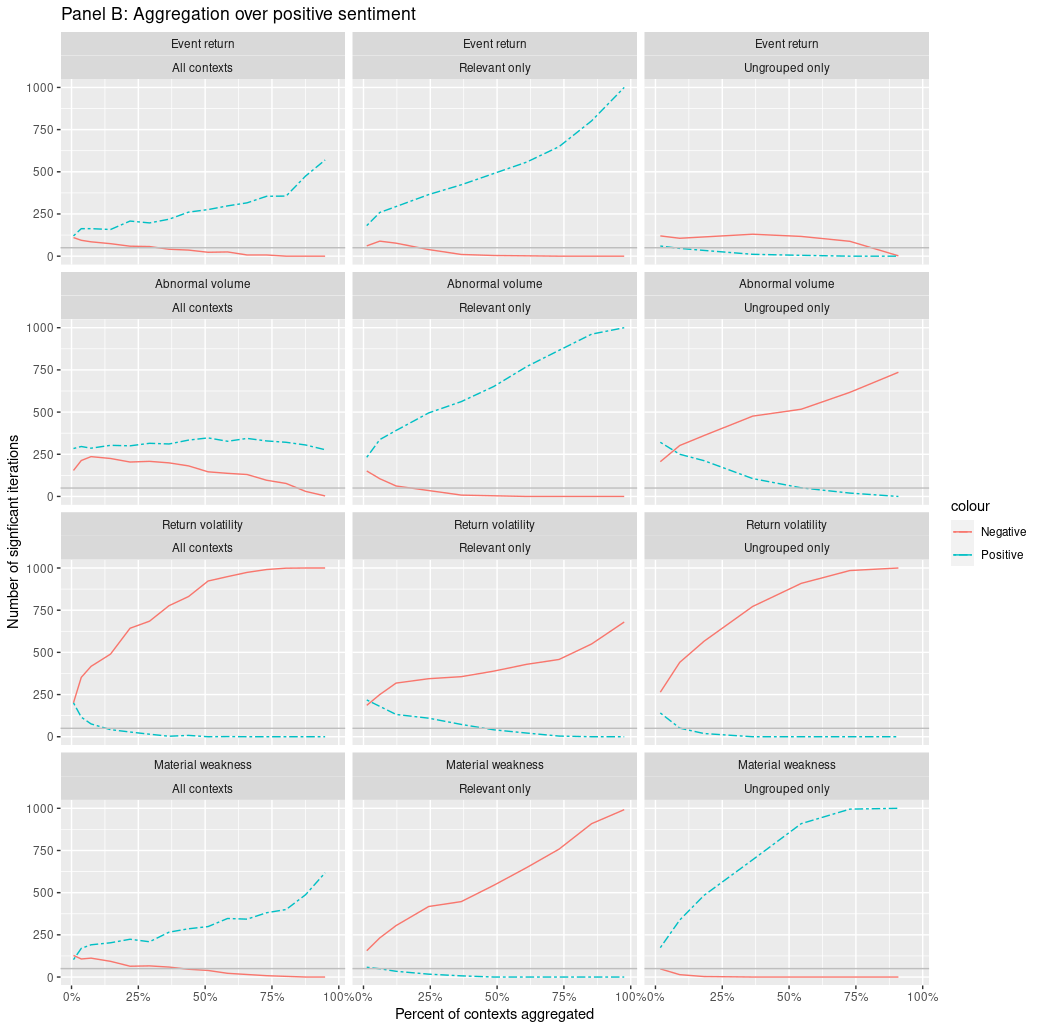
- Only a few key contexts drive each financial sentiment result
- Aggregation to document-level sentiment adds a lot of noise
- Sentiment, at the context level, often contradicts prior results
- Aggregation removes nuance from our understanding
- Different contexts drive prediction for different DVs
- Sentiment captures different empirical constructs in different regressions
- The above results hold across 2 other financial sentiment dictionaries
- Our results are not unique to the LM dictionary
- The above results hold using a neural network-based sentiment measure
- Bag-of-words isn’t the problem – financial sentiment, as a construct, likely is
Punchline: Sentiment should be measured on fine-grained contexts, not full documents
- In other words, a precise matching between the text used and the economic question examined is needed