ACCT 420: Project example
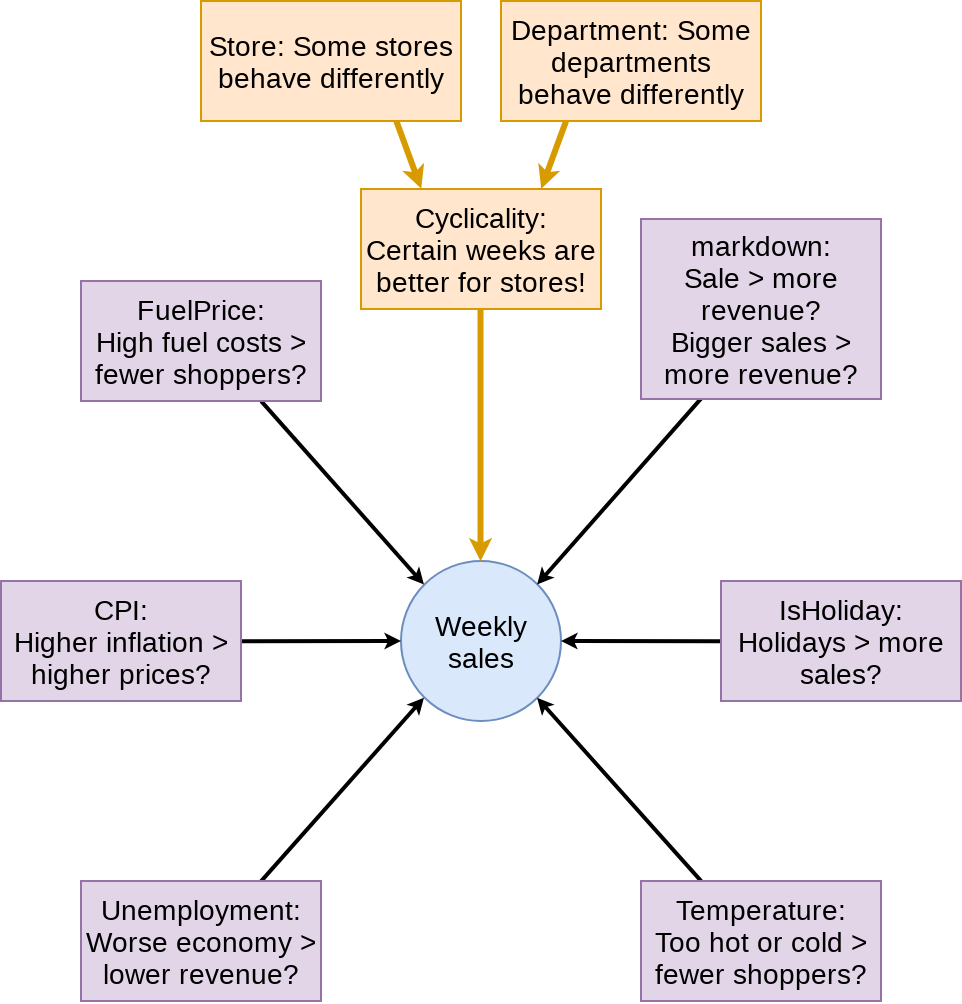
Cleaning: Missing CPI and Unemployment
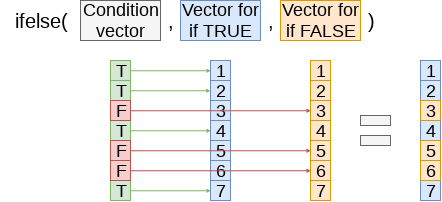
Apply the (year, Store)’s CPI and Unemployment to missing data
Cleaning is done
- Data is in order
- No missing values where data is needed
- Needed values created
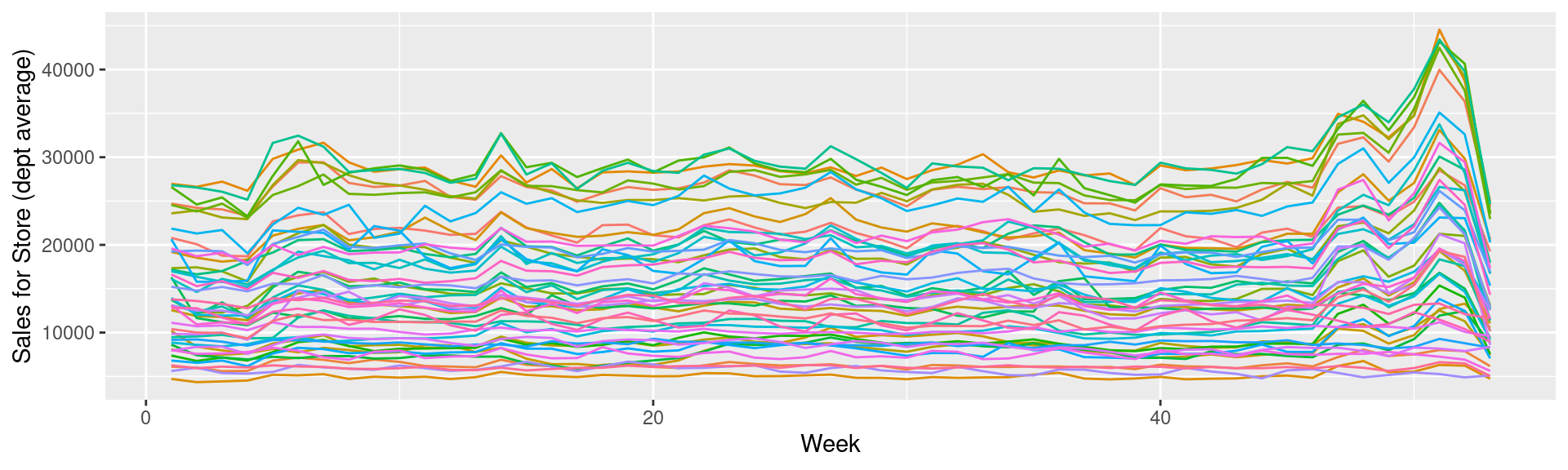
First try
- Ideal: Use last week to predict next week!

No data for testing…
- First instinct: try to use a linear regression to solve this

We have this
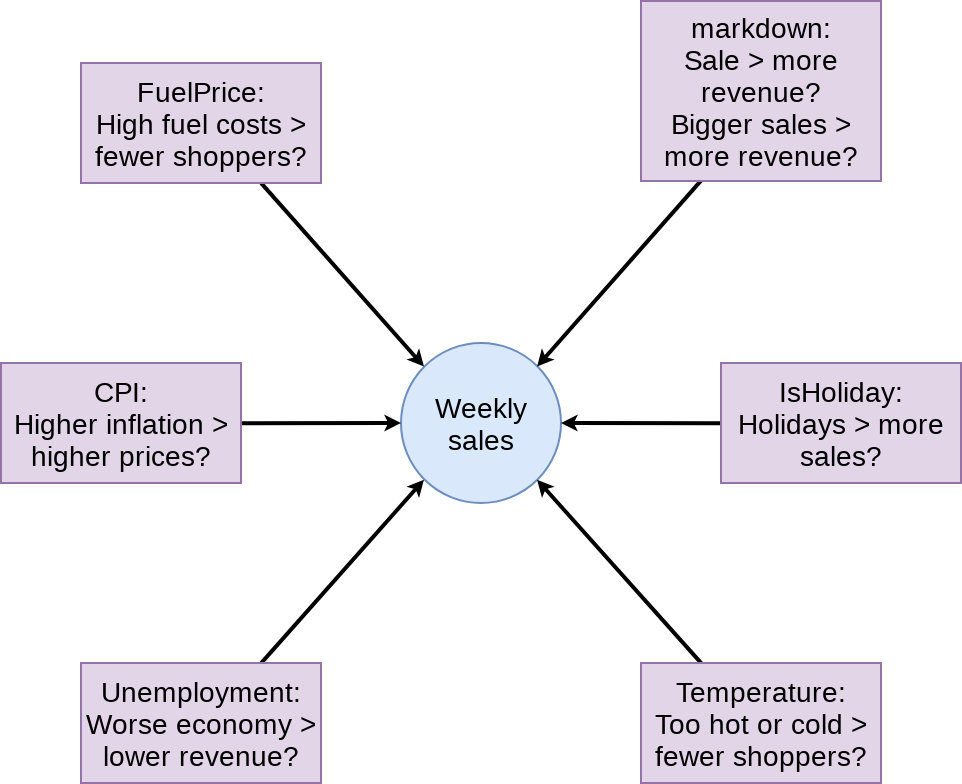
What to put in the model?
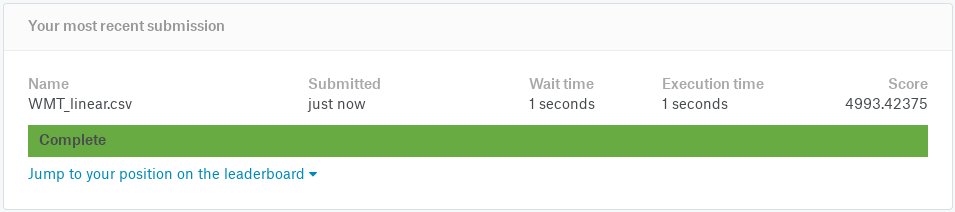
Performance for linear model
![]()
Visualizing in sample WMAE
wmae_obs <- function(actual, predicted, holidays) {
abs(actual-predicted)*(holidays*5+1) / (length(actual) + 4*sum(holidays))
}
df$wmaes <- wmae_obs(actual=df$Weekly_Sales, predicted=df$WS_linear,
holidays=df$IsHoliday)
ggplot(data=df, aes(y=wmaes, x=week, color=factor(IsHoliday))) +
geom_jitter(width=0.25) + xlab("Week") + ylab("WMAE")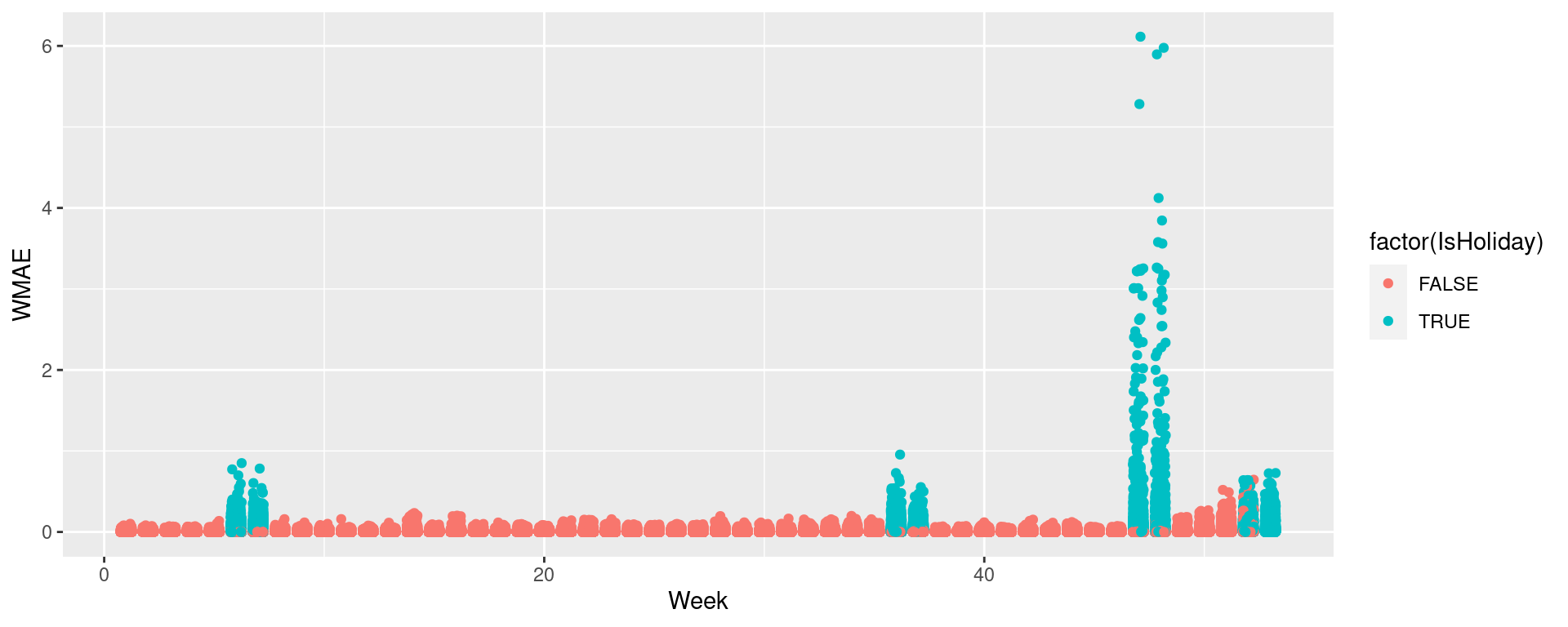
Back to the drawing board…
Performance for linear model 2
![]()
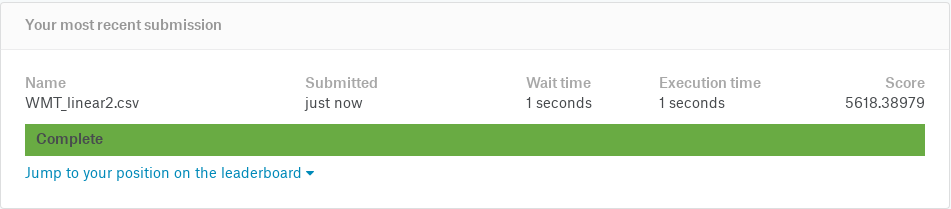
wmaes_out Linear Linear 2
4993.4 5618.4 Visualizing in sample WMAE
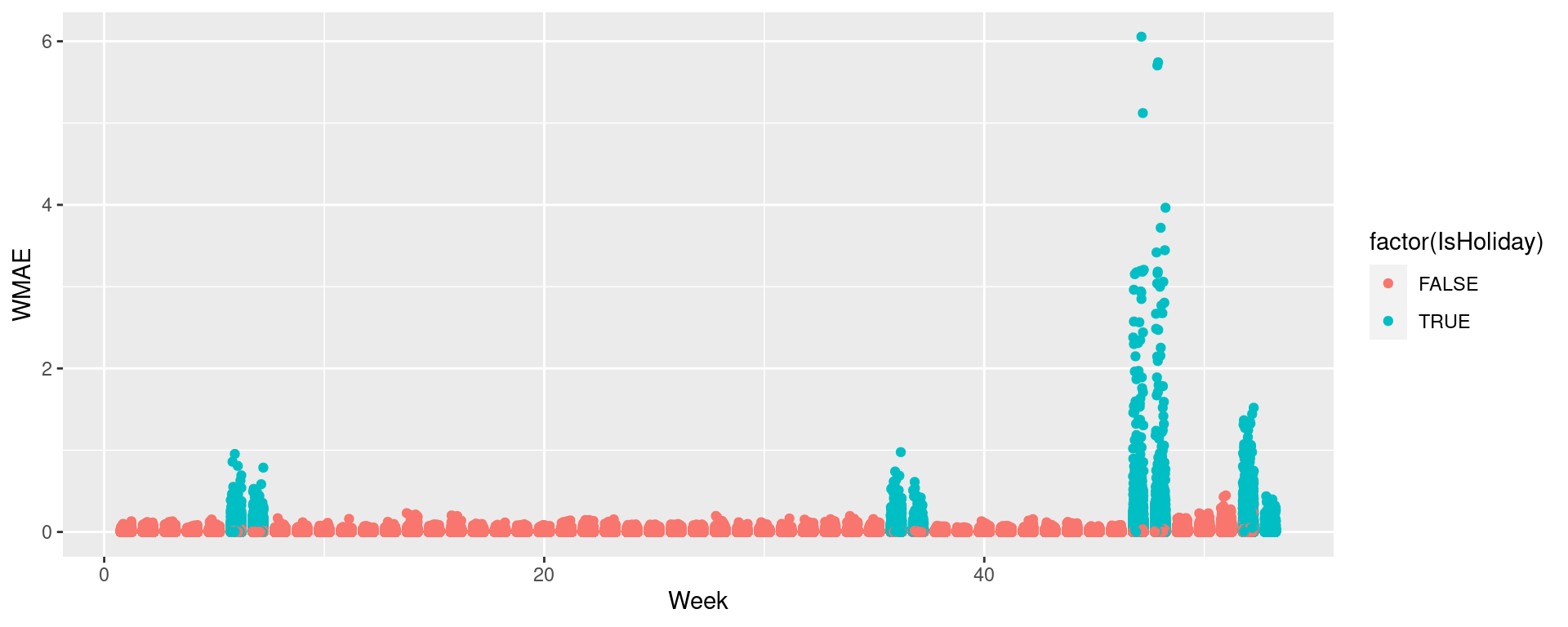
Visualizing in sample WMAE by Store
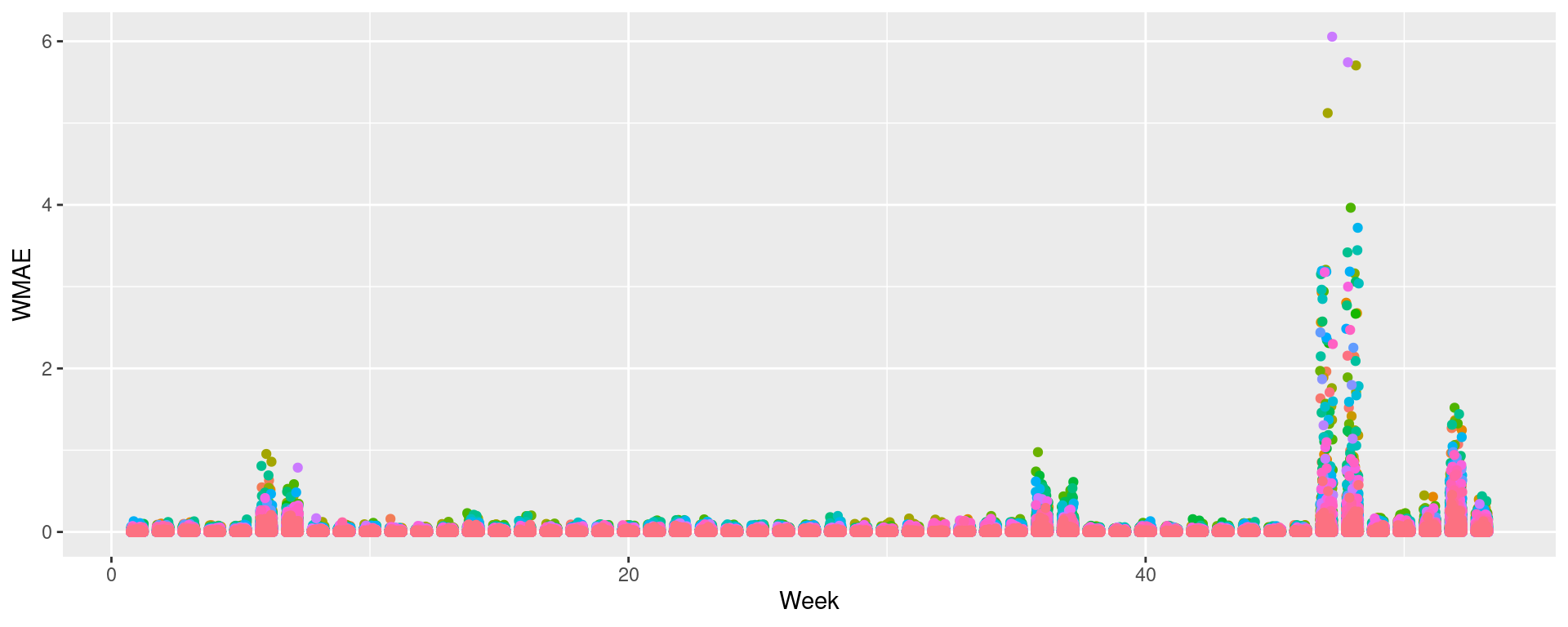
Visualizing in sample WMAE by Dept
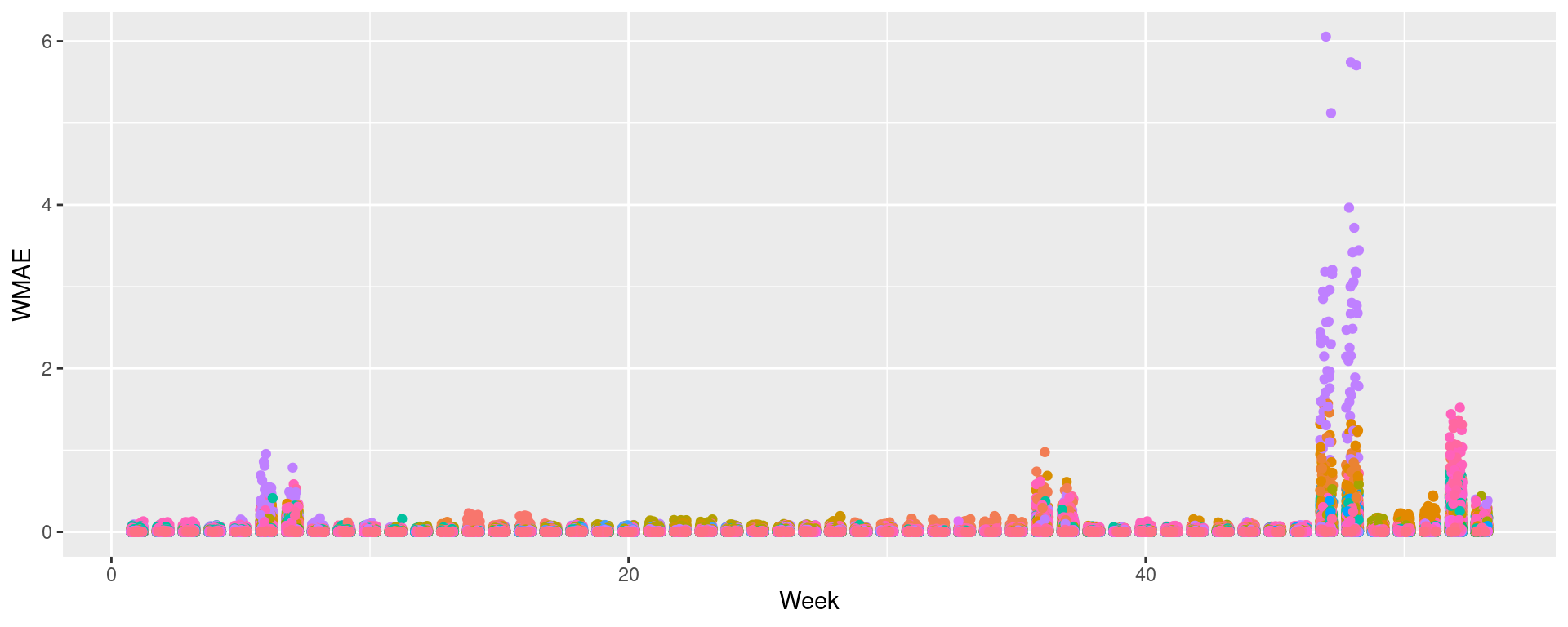
Back to the drawing board…
Performance for FE model
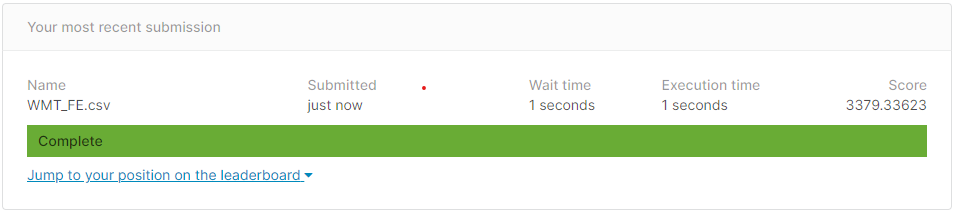
![]()
wmaes_out Linear Linear 2 FE
4993.4 5618.4 3379.3 Visualizing in sample WMAE
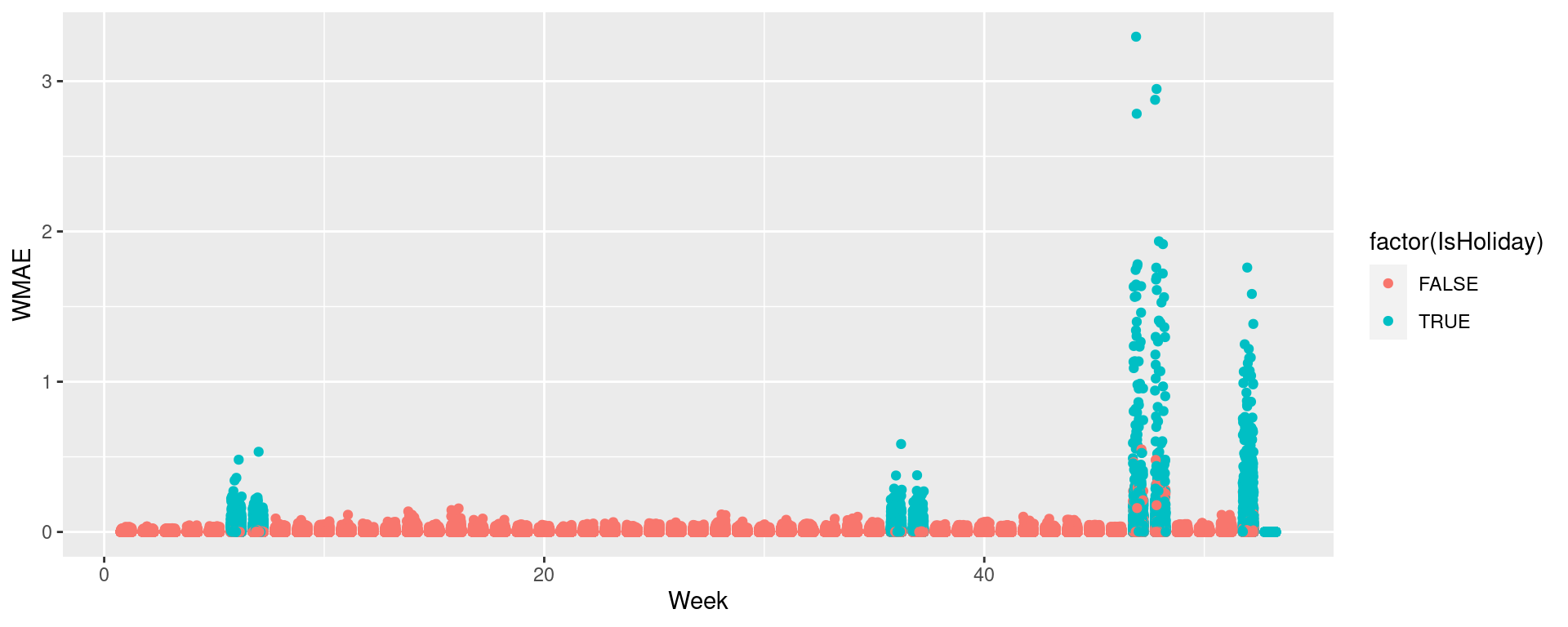
Performance overall
![]()
wmaes_out Linear Linear 2 FE Shifted FE
4993.4 5618.4 3378.8 3274.8 NOTES
![]()