
ACCT 420: Course Logistics + R Refresh
Learning objectives

-
Theory:
- What is analytics?
-
Application:
- Who uses analytics? (and why?)
-
Methodology:
- Review of R
- Almost every class will touch on each of these three aspects
Teaching
- At SMU since 2016
- Teaching:
- IDIS 700, Machine Learning for Social Science
- A country-wide PhD course on empirical machine learning
- ACCT 703, Analytical Methods in Accounting
- Theory of accounting through the lenses of economics, history, and philosophy
- ACCT 420, Forecasting and Forensic Analytics
- Your are here!
- ACCT 101, Financial Accounting
- IDIS 700, Machine Learning for Social Science
- Before SMU: Completed my PhD at University of Illinois Urbana-Champaign
![]()

Research
- Accounting disclosure: What companies say, and why it matters
- Focus on social media and regulatory filings
- Approach this using AI/ML techniques




What will this course cover?
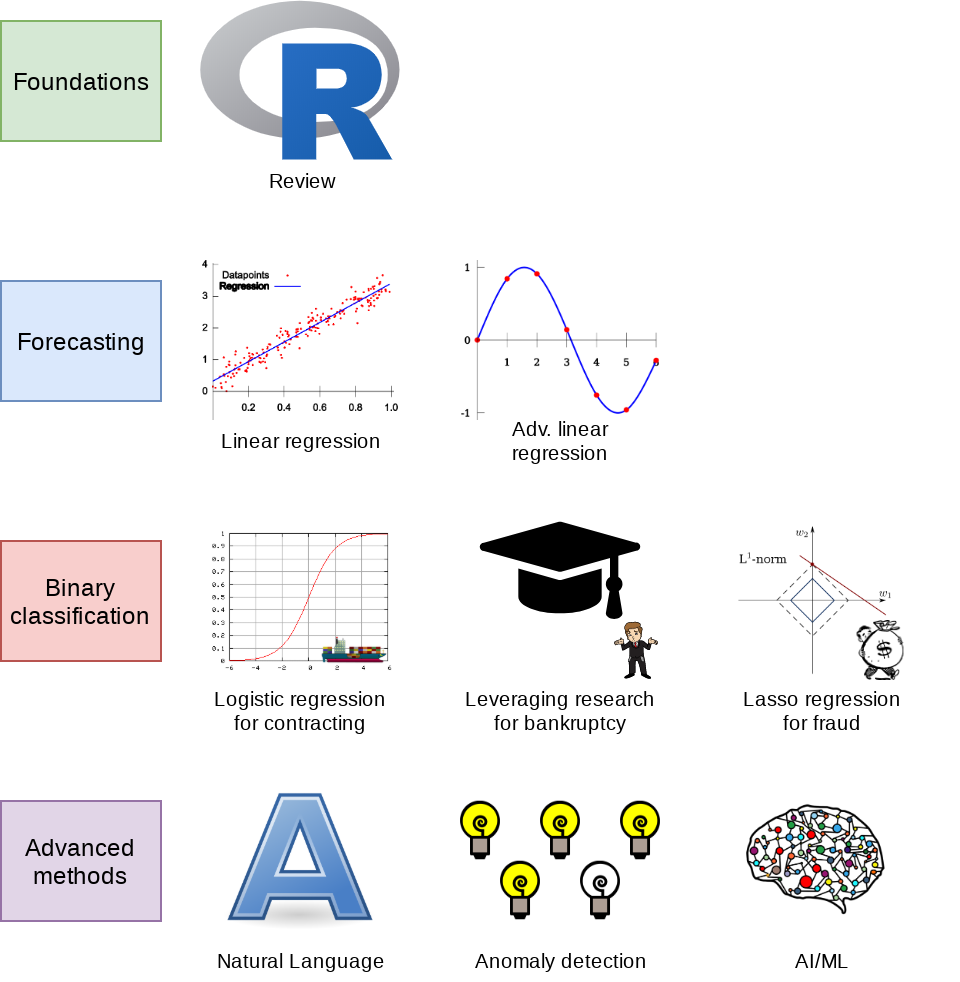
- Foundations (today)
- Thinking about analytics
- In class: Setting a foundation for the course
- Outside: Practice and refining skills on Datacamp
- Pick any R course, any level, and try it out!
- Financial forecasting
- Predict financial outcomes
- Linear models
Getting familiar with forecasting using real data and R
What will this course cover?
- Binary classification
- Event prediction
- Classification & detection
- Advanced methods
- Non-numeric data (text)
- Clustering
- AI/Machine learning (AI/ML)
- Ethics of AI
- Current developments, including LLMs (e.g., ChatGPT)
Higher level financial forecasting, detection, and AI/ML
Textbook
- There is no required textbook
- Datacamp is taking the place of the textbook
- If you prefer having a textbook…
- R for Everyone by Jared Lander is a good one on R

- Other course materials (slides and articles) are available at:
- eLearn
-
https://rmc.link/acct420
- This includes html versions of the slides with interactive content
- Announcements will be only on eLearn
Group project
- Data science competition format, hosted on Kaggle
- Multiple options for the project will be available
- The project will start on session 7
- The project will finish on session 12 with group presentations
![]()
Likely schedule adjustment
Expect one class session to be cancelled in mid-to-late October
- Some class session may be moved to Zoom as well, as needed

Learning objectives
-
Theory:
- What is analytics?
-
Application:
- Who uses analytics? (and why?)
-
Methodology:
- Review of R
*Almost every class will touch on each of these three aspects
Analytics vs AI/machine learning

- In class reading:
- AI Will Enhance Us, Not Replace Us
- By DataRobot’s VP of AI Strategy
- Short link: rmc.link/420class1
How will Analytics/AI/ML change society and the accounting profession?
What are forecasting analytics?
- Forecasting is about making an educated guess of events to come in the future
- Who will win the next soccer game?
- What stock will have the best (risk-adjusted) performance?
- What will Singtel’s earnings be next quarter?
- Leverage past information
- Implicitly assumes that the past and the future predictably related

Forecasting analytics in this class
- Revenue/sales
- Shipping delays
- Bankruptcy
- Machine learning applications

What are forensic analytics?
- Forensic analytics focus on detection
- Detecting crime such as bribery
- Detecting fraud within companies
- Looking at a lot of dog pictures to identify features unique to each breed

Forensic analytics in this class
- Fraud detection
- Working with textual data
- Detecting changes
- Machine learning applications

What do companies use analytics for?
- Customer service
-
Royal Bank of Scotland
- Understanding customer complaints
-
Royal Bank of Scotland
- Improving products
- Siemens’ Internet of Trains
- Improving train reliability
- Siemens’ Internet of Trains
- Their business
-
$18.3B USD market in 2017
- Just a small portion of overall IT spending ($3.7T USD)
-
$18.3B USD market in 2017

![]()
![]()
What do governments use analytics for?
- Govtech
- Open data
-
AI Singapore
- Talent matching
- Grand Challenges


![]()
What do academics use analytics for?

- Tweeting frequency by S&P 1500 companies (paper)
- Aggregates every tweet from 2012 to 2016
- Shows frequency in 5 minute chunks
- Note the spikes every hour!
- The white part is the time the NYSE is open
What do academics use analytics for?
- Annual report content that predicts fraud (paper)
- For instance, discussing income is useful
- first row is decreases, second is increases
- But if it’s good or bad depends on the year
- For instance, in 1999 it is a red flag
- And one that Enron is flagged for

What do individuals use analytics for?

- Consulting
- Radim Rehurek: Maintainer of gensim, freelance consultant
- Investing
- Health
- Smart watches and other wearables
What is R?
- R is a “statistical programming language”
- Focused on data handling, calculation, data analysis, and visualization
- We will use R for all work in this course

Alternatives to R
![]()
- Extremely popular
- Free and open source
- Very strong AI/ML support
![]()


![]()
![]()
- Fast and free
- Mathematics oriented
- Still young though
![]()
- Fast and free
- Focused on scalability, basis of Apache Spark
How to use R Studio
- R markdown or Quarto file
- You can write out reports with embedded analytics
- Console
- Useful for testing code and exploring your data
- Enter your code one line at a time
- R Markdown console
- Shows if there are any errors when preparing your report

How to use R Studio
- Environment
- Shows all the values you have stored
- Help
- Can search documentation for instructions on how to use a function
- Viewer
- Shows any output you have at the moment.
- Files
- Shows files on your computer

Data Sources
- WRDS
- WRDS is a provider of business data for academic purposes
- Through your class account, you can access vast amounts of data
- We will be particularly interested in:
- Compustat (accounting statement data since 1950)
- CRSP (stock price data, daily since 1926)
- We will use other public data from time to time
- Singapore’s big data repository
- US Government data
- Other public data collected by the Prof


Go to WRDS and sign in

Pick a data provider, e.g. “Compustat - Capital IQ”

Pick a data set, e.g. “North America - Daily”

Pick a data set, e.g. “Fundamentals Annual”

Selecting data: Time range

Selecting data: Companies and data format

Selecting data fields

Select output formats

Wait for the data to be prepared

Download the data!

![]()