columns <- c("Google", "Microsoft",
"Goldman")
rows <- c("Earnings","Revenue")
firm_data <- matrix(data=
c(12662, 21204, 4286, 110855,
89950, 42254), nrow=2)
# Equivalent:
# matrix(data=c(12662, 21204, 4286,
# 110855, 89950, 42254), ncol=3)
# Apply names
rownames(firm_data) <- rows
colnames(firm_data) <- columns
# Print the matrix
firm_data
## Google Microsoft Goldman
## Earnings 12662 4286 89950
## Revenue 21204 110855 42254
## [1] 42254
firm_data[, c("Google", "Microsoft")]
## Google Microsoft
## Earnings 12662 4286
## Revenue 21204 110855
## Google Microsoft Goldman
## 12662 4286 89950
firm_data["Revenue", "Goldman"]
## [1] 42254
Combining matrices
- Matrices are combined top to bottom as rows with rbind()
- Matrices are combined side-by-side as columns with cbind()
# Preloaded: industry codes as indcode (vector)
# - GICS codes: 40=Financials, 45=Information Technology
# - See: https://en.wikipedia.org/wiki/Global_Industry_Classification_Standard
# Preloaded: JPMorgan data as jpdata (vector)
mat <- rbind(firm_data,indcode) # Add a row
rownames(mat)[3] <- "Industry" # Name the new row
mat
## Google Microsoft Goldman
## Earnings 12662 4286 89950
## Revenue 21204 110855 42254
## Industry 45 45 40
mat <- cbind(firm_data,jpdata) # Add a column
colnames(mat)[4] <- "JPMorgan" # Name the new column
mat
## Google Microsoft Goldman JPMorgan
## Earnings 12662 4286 89950 17370
## Revenue 21204 110855 42254 115475
Lists: What are they?
- Like vectors, but with mixed types
- Generally not something we will create
- Often returned by analysis functions in R
- Such as the linear models we will look at next week
# Ignore this code for now...
model <- summary(lm(earnings ~ revenue, data=tech_df))
#Note that this function is hiding something...
model
##
## Call:
## lm(formula = earnings ~ revenue, data = tech_df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -16045.0 20.0 141.6 177.1 12104.6
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.837e+02 4.491e+01 -4.091 4.79e-05 ***
## revenue 1.589e-01 3.564e-03 44.585 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1166 on 713 degrees of freedom
## Multiple R-squared: 0.736, Adjusted R-squared: 0.7356
## F-statistic: 1988 on 1 and 713 DF, p-value: < 2.2e-16
Looking into lists
- Lists generally use double square brackets,
[[index]]
- Used for pulling individual elements out of a list
[[c()]] will drill through lists, as opposed to pulling multiple values- Single square brackets pull out elements as is
- Double square brackets extract just the element
- For 1 level, we can also use
$
## $r.squared
## [1] 0.7360059
## [1] 0.7360059
## [1] 0.7360059
earnings <- c(12662, 21204, 4286)
company <- c("Google", "Microsoft", "Goldman")
names(earnings) <- company
earnings["Google"]
## Google
## 12662
## [1] 12662
#Can't use $ with vectors
Structure of a list
- str() will tell us what’s in this list
## List of 11
## $ call : language lm(formula = earnings ~ revenue, data = tech_df)
## $ terms :Classes 'terms', 'formula' language earnings ~ revenue
## .. ..- attr(*, "variables")= language list(earnings, revenue)
## .. ..- attr(*, "factors")= int [1:2, 1] 0 1
## .. .. ..- attr(*, "dimnames")=List of 2
## .. .. .. ..$ : chr [1:2] "earnings" "revenue"
## .. .. .. ..$ : chr "revenue"
## .. ..- attr(*, "term.labels")= chr "revenue"
## .. ..- attr(*, "order")= int 1
## .. ..- attr(*, "intercept")= int 1
## .. ..- attr(*, "response")= int 1
## .. ..- attr(*, ".Environment")=<environment: R_GlobalEnv>
## .. ..- attr(*, "predvars")= language list(earnings, revenue)
## .. ..- attr(*, "dataClasses")= Named chr [1:2] "numeric" "numeric"
## .. .. ..- attr(*, "names")= chr [1:2] "earnings" "revenue"
## $ residuals : Named num [1:715] -59.7 173.8 -620.2 586.7 613.6 ...
## ..- attr(*, "names")= chr [1:715] "1" "2" "3" "4" ...
## $ coefficients : num [1:2, 1:4] -1.84e+02 1.59e-01 4.49e+01 3.56e-03 -4.09 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : chr [1:2] "(Intercept)" "revenue"
## .. ..$ : chr [1:4] "Estimate" "Std. Error" "t value" "Pr(>|t|)"
## $ aliased : Named logi [1:2] FALSE FALSE
## ..- attr(*, "names")= chr [1:2] "(Intercept)" "revenue"
## $ sigma : num 1166
## $ df : int [1:3] 2 713 2
## $ r.squared : num 0.736
## $ adj.r.squared: num 0.736
## $ fstatistic : Named num [1:3] 1988 1 713
## ..- attr(*, "names")= chr [1:3] "value" "numdf" "dendf"
## $ cov.unscaled : num [1:2, 1:2] 1.48e-03 -2.83e-08 -2.83e-08 9.35e-12
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : chr [1:2] "(Intercept)" "revenue"
## .. ..$ : chr [1:2] "(Intercept)" "revenue"
## - attr(*, "class")= chr "summary.lm"
What are data frames?
- Data frames are like a hybrid between lists and matrices
Like a matrix:
- 2 dimensional like matrices
- Can access data with
[]
- All elements in a column must be the same data type
Like a list:
- Can have different data types for different columns
- Can access data with
$
Columns \(\approx\) variables, e.g., earnings
Rows \(\approx\) observations, e.g., Google in 2017
Dealing with data frames
There are three schools of thought on this
- Use Base R functions (i.e., what’s built in)
- Use tidy methods (from tidyverse)
- Almost always cleaner and more readable
- Sometimes faster, sometimes slower
- This creates a structure called a
tibble
- Use data.table (from data.table)
- Very structured syntax, but difficult to read
- Almost always fastest – use when speed is needed
- This creates a structure called a
data.table
Cast either to a data.frame using as.data.frame()
Data in Base R
Note: Base R methods are explained in the R Supplement
library(tidyverse) # Imports most tidy packages
# Base R data import -- stringsAsFactors is important here
df <- read.csv("../../Data/Session_1-2.csv", stringsAsFactors=FALSE)
df <- subset(df, fyear == 2017 & !is.na(revt) & !is.na(ni) &
revt > 1 & gsector == 45)
df$margin = df$ni / df$revt
summary(df)
## gvkey datadate fyear indfmt
## Min. : 1072 Min. :20170630 Min. :2017 Length:715
## 1st Qu.: 20231 1st Qu.:20171231 1st Qu.:2017 Class :character
## Median : 33232 Median :20171231 Median :2017 Mode :character
## Mean : 79699 Mean :20172029 Mean :2017
## 3rd Qu.:148393 3rd Qu.:20171231 3rd Qu.:2017
## Max. :315629 Max. :20180430 Max. :2017
##
## consol popsrc datafmt tic
## Length:715 Length:715 Length:715 Length:715
## Class :character Class :character Class :character Class :character
## Mode :character Mode :character Mode :character Mode :character
##
##
##
##
## conm curcd ni revt
## Length:715 Length:715 Min. :-4307.49 Min. : 1.06
## Class :character Class :character 1st Qu.: -15.98 1st Qu.: 102.62
## Mode :character Mode :character Median : 1.84 Median : 397.57
## Mean : 296.84 Mean : 3023.78
## 3rd Qu.: 91.36 3rd Qu.: 1531.59
## Max. :48351.00 Max. :229234.00
##
## cik costat gind gsector
## Min. : 2186 Length:715 Min. :451010 Min. :45
## 1st Qu.: 887604 Class :character 1st Qu.:451020 1st Qu.:45
## Median :1102307 Mode :character Median :451030 Median :45
## Mean :1086969 Mean :451653 Mean :45
## 3rd Qu.:1405497 3rd Qu.:452030 3rd Qu.:45
## Max. :1725579 Max. :453010 Max. :45
## NA's :3
## gsubind margin
## Min. :45101010 Min. :-13.97960
## 1st Qu.:45102020 1st Qu.: -0.10253
## Median :45103020 Median : 0.01353
## Mean :45165290 Mean : -0.10967
## 3rd Qu.:45203012 3rd Qu.: 0.09295
## Max. :45301020 Max. : 1.02655
##
Data the tidy way
# Tidy import
df <- read_csv("../../Data/Session_1-2.csv") %>%
filter(fyear == 2017, # fiscal year
!is.na(revt), # revenue not missing
!is.na(ni), # net income not missing
revt > 1, # at least 1M USD in revenue
gsector == 45) %>% # tech firm
mutate(margin = ni/revt) # profit margin
summary(df)
## gvkey datadate fyear indfmt
## Length:715 Min. :20170630 Min. :2017 Length:715
## Class :character 1st Qu.:20171231 1st Qu.:2017 Class :character
## Mode :character Median :20171231 Median :2017 Mode :character
## Mean :20172029 Mean :2017
## 3rd Qu.:20171231 3rd Qu.:2017
## Max. :20180430 Max. :2017
## consol popsrc datafmt tic
## Length:715 Length:715 Length:715 Length:715
## Class :character Class :character Class :character Class :character
## Mode :character Mode :character Mode :character Mode :character
##
##
##
## conm curcd ni revt
## Length:715 Length:715 Min. :-4307.49 Min. : 1.06
## Class :character Class :character 1st Qu.: -15.98 1st Qu.: 102.62
## Mode :character Mode :character Median : 1.84 Median : 397.57
## Mean : 296.84 Mean : 3023.78
## 3rd Qu.: 91.36 3rd Qu.: 1531.59
## Max. :48351.00 Max. :229234.00
## cik costat gind gsector
## Length:715 Length:715 Min. :451010 Min. :45
## Class :character Class :character 1st Qu.:451020 1st Qu.:45
## Mode :character Mode :character Median :451030 Median :45
## Mean :451653 Mean :45
## 3rd Qu.:452030 3rd Qu.:45
## Max. :453010 Max. :45
## gsubind margin
## Min. :45101010 Min. :-13.97960
## 1st Qu.:45102020 1st Qu.: -0.10253
## Median :45103020 Median : 0.01353
## Mean :45165290 Mean : -0.10967
## 3rd Qu.:45203012 3rd Qu.: 0.09295
## Max. :45301020 Max. : 1.02655
Other important tidy methods
- Sorting: use arrange()
- Grouping for calculations:
- Keep only a subset of variables using select()
- We’ll see many more along the way!
A note on syntax: Piping
Pipe notation is never necessary and not built in to R
- Piping comes from magrittr
- Pipe notation is done using
%>%
Left %>% Right(arg2, ...) is the same as Right(Left, arg2, ...)
Piping can drastically improve code readability
- magrittr has other interesting pipes, such as
%<>%
Left %<>% Right(arg2, ...) is the same as Left <- Right(Left, arg2, ...)
Tidy example without piping
Note how unreadable this gets (but output is the same)
df <- mutate(
filter(
read_csv("../../Data/Session_1-2.csv"),
fyear == 2017, # fiscal year
!is.na(revt), # revenue not missing
!is.na(ni), # net income not missing
revt > 1, # at least 1M USD in revenue
gsector == 45), # tech firm
margin = ni/revt) # profit margin
summary(df)
## gvkey datadate fyear indfmt
## Length:715 Min. :20170630 Min. :2017 Length:715
## Class :character 1st Qu.:20171231 1st Qu.:2017 Class :character
## Mode :character Median :20171231 Median :2017 Mode :character
## Mean :20172029 Mean :2017
## 3rd Qu.:20171231 3rd Qu.:2017
## Max. :20180430 Max. :2017
## consol popsrc datafmt tic
## Length:715 Length:715 Length:715 Length:715
## Class :character Class :character Class :character Class :character
## Mode :character Mode :character Mode :character Mode :character
##
##
##
## conm curcd ni revt
## Length:715 Length:715 Min. :-4307.49 Min. : 1.06
## Class :character Class :character 1st Qu.: -15.98 1st Qu.: 102.62
## Mode :character Mode :character Median : 1.84 Median : 397.57
## Mean : 296.84 Mean : 3023.78
## 3rd Qu.: 91.36 3rd Qu.: 1531.59
## Max. :48351.00 Max. :229234.00
## cik costat gind gsector
## Length:715 Length:715 Min. :451010 Min. :45
## Class :character Class :character 1st Qu.:451020 1st Qu.:45
## Mode :character Mode :character Median :451030 Median :45
## Mean :451653 Mean :45
## 3rd Qu.:452030 3rd Qu.:45
## Max. :453010 Max. :45
## gsubind margin
## Min. :45101010 Min. :-13.97960
## 1st Qu.:45102020 1st Qu.: -0.10253
## Median :45103020 Median : 0.01353
## Mean :45165290 Mean : -0.10967
## 3rd Qu.:45203012 3rd Qu.: 0.09295
## Max. :45301020 Max. : 1.02655
Practice: Data types and structures
- This practice is to make sure you understand data types
- Do exercises 1 through 3 on today’s R practice file:
Reference
Many useful functions are highlighted in the R Supplement
- Installing and loading packages
# Install the tidyverse package from inside R
install.packages("tidyverse")
# Load the package
library(tidyverse)
- Help functions
# To see a help page for a function (such as data.frame()) run either of:
help(data.frame)
?data.frame
# To see the arguments a function takes, run:
args(data.frame)
## function (..., row.names = NULL, check.rows = FALSE, check.names = TRUE,
## fix.empty.names = TRUE, stringsAsFactors = FALSE)
## NULL
Making your own functions!
- Use the function() function!
my_func <- function(agruments) {code}
Simple function: Add 2 to a number
add_two <- function(n) {
n + 2
}
add_two(500)
## [1] 502
Slightly more complex function example
mult_together <- function(n1, n2=0, square=FALSE) {
if (!square) {
n1 * n2
} else {
n1 * n1
}
}
mult_together(5,6)
## [1] 30
mult_together(5,6,square=TRUE)
## [1] 25
mult_together(5,square=TRUE)
## [1] 25
Example: Currency conversion function
FXRate <- function(from="USD", to="SGD", dt=Sys.Date()) {
options("getSymbols.warning4.0"=FALSE)
require(quantmod)
data <- getSymbols(paste0(from, "/", to), from=dt-3, to=dt, src="oanda", auto.assign=F)
return(data[[1]])
}
date()
## [1] "Sun Aug 15 23:41:31 2021"
FXRate(from="USD", to="SGD") # Today's SGD to USD rate
## [1] 1.357472
FXRate(from="SGD", to="CNY") # Today's SGD to CNY rate
## [1] 4.772041
FXRate(from="USD", to="SGD", dt=Sys.Date()-90) # Last quarter's SGD to USD rate
## [1] 1.333589
Practice: Functions
- This practice is to make sure you understand functions and their construction
- Do exercises 4 and 5 on today’s R practice file:
Wrap up
- For next week:
- Take a look at Datacamp!
- Be sure to complete the assignment there
- A complete list of assigned modules over the course is on eLearn
- We’ll start in on some light analytics next week
- Survey on the class session at rmc.link/420survey1
Packages used for these slides
How to download from WRDS
- Log in using a class account (posted on eLearn)
- Pick the data provider that has your needed data
- Select the data set you would like (some data sets only)
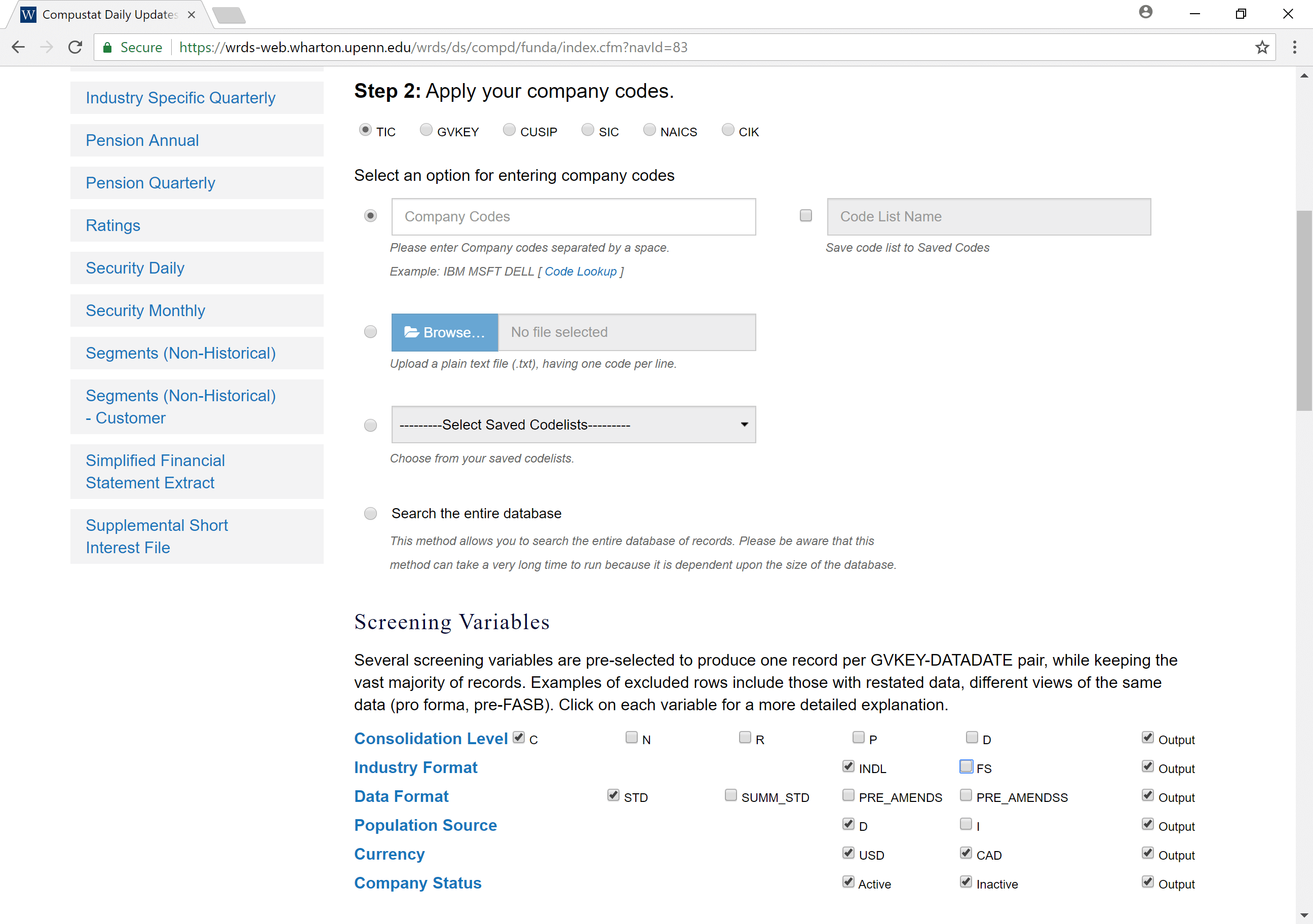
- Apply any needed conditional restrictions (years, etc.)
- These can help keep data sizes manageable
- CRSP without any restrictions is >10 GB
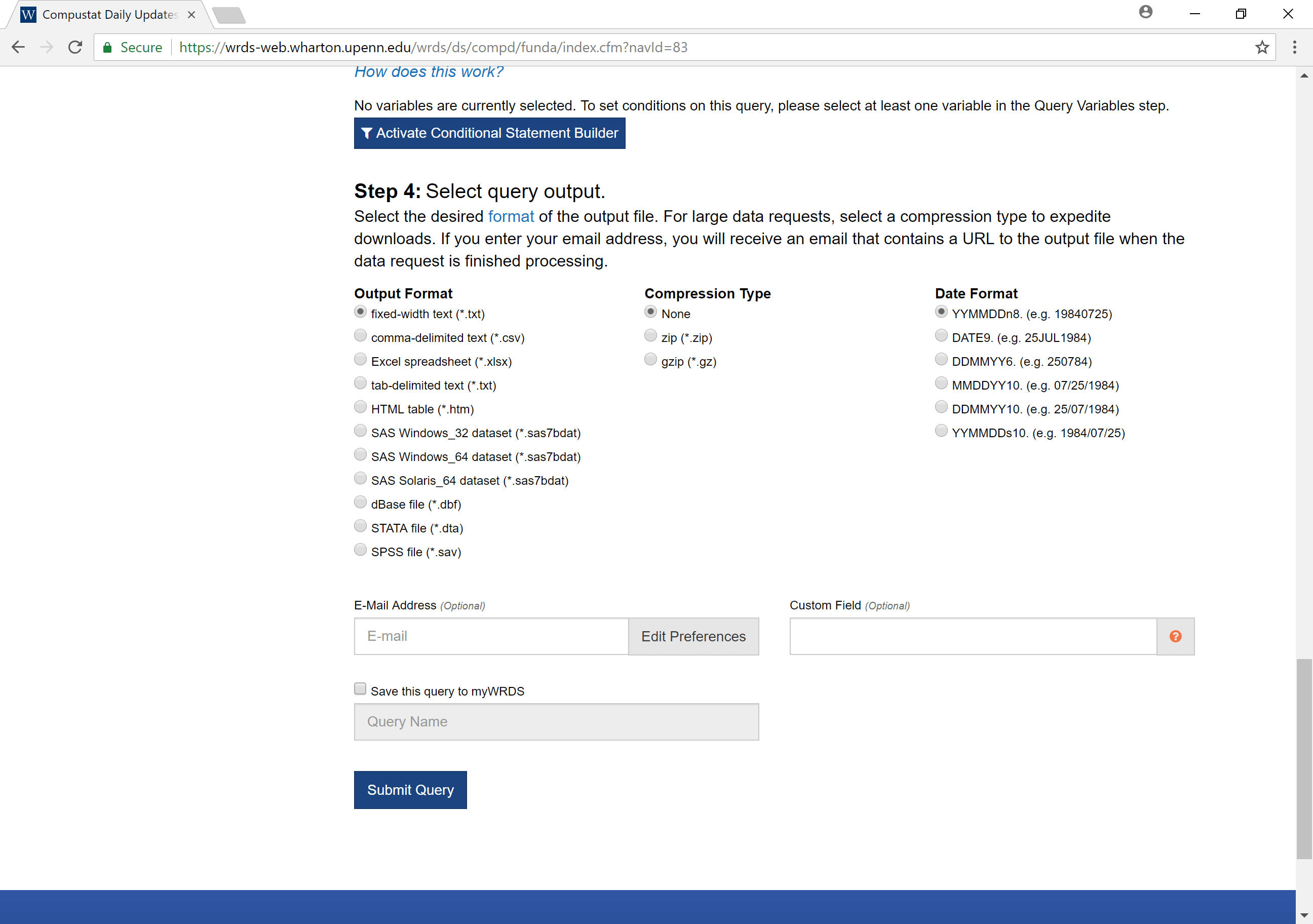
- Select the specific variables you would like export
- Export as a csv file, zipped csv file (or other format)
Go to WRDS and sign in

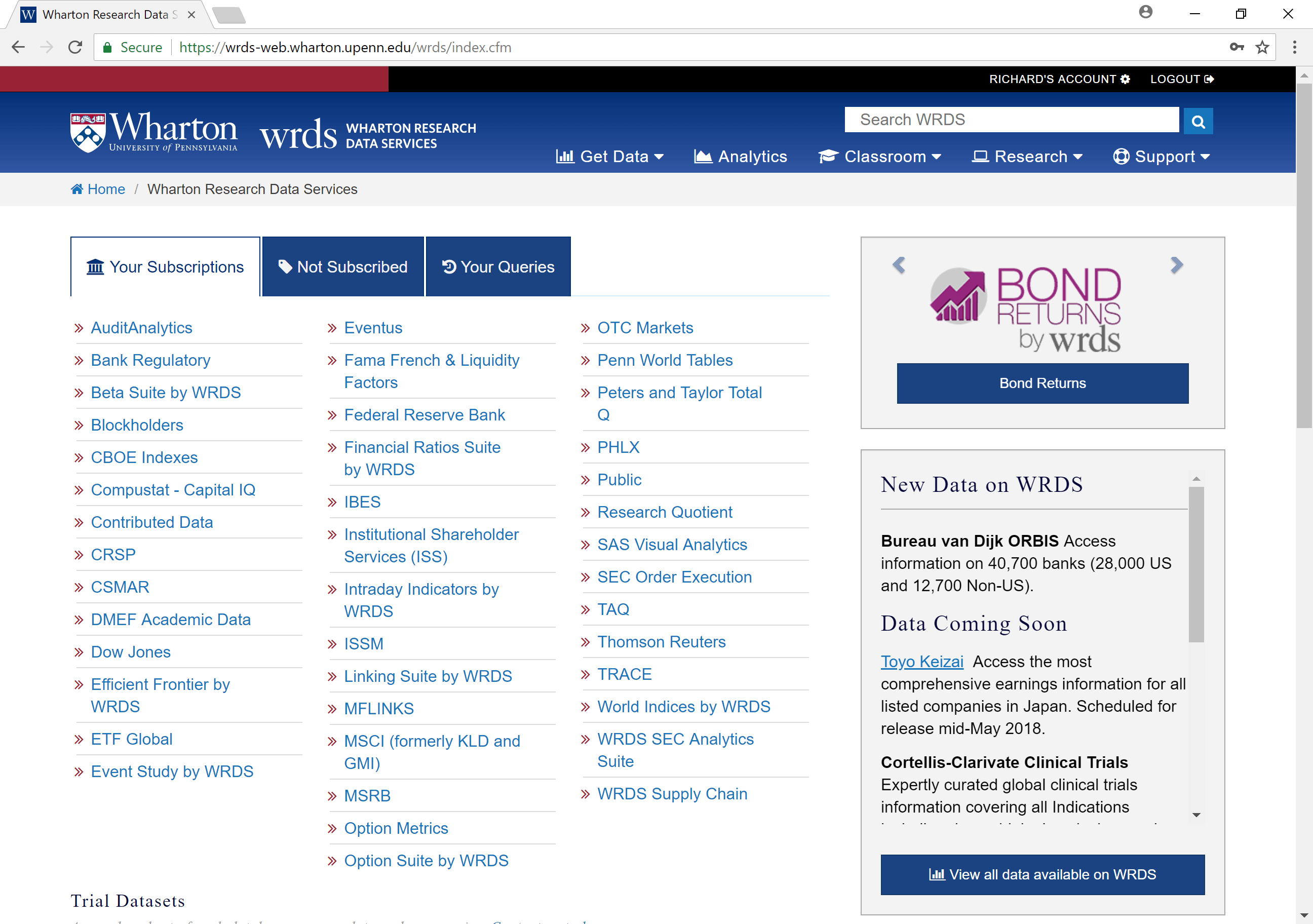
Pick a data provider, e.g. “Compustat - Capital IQ”
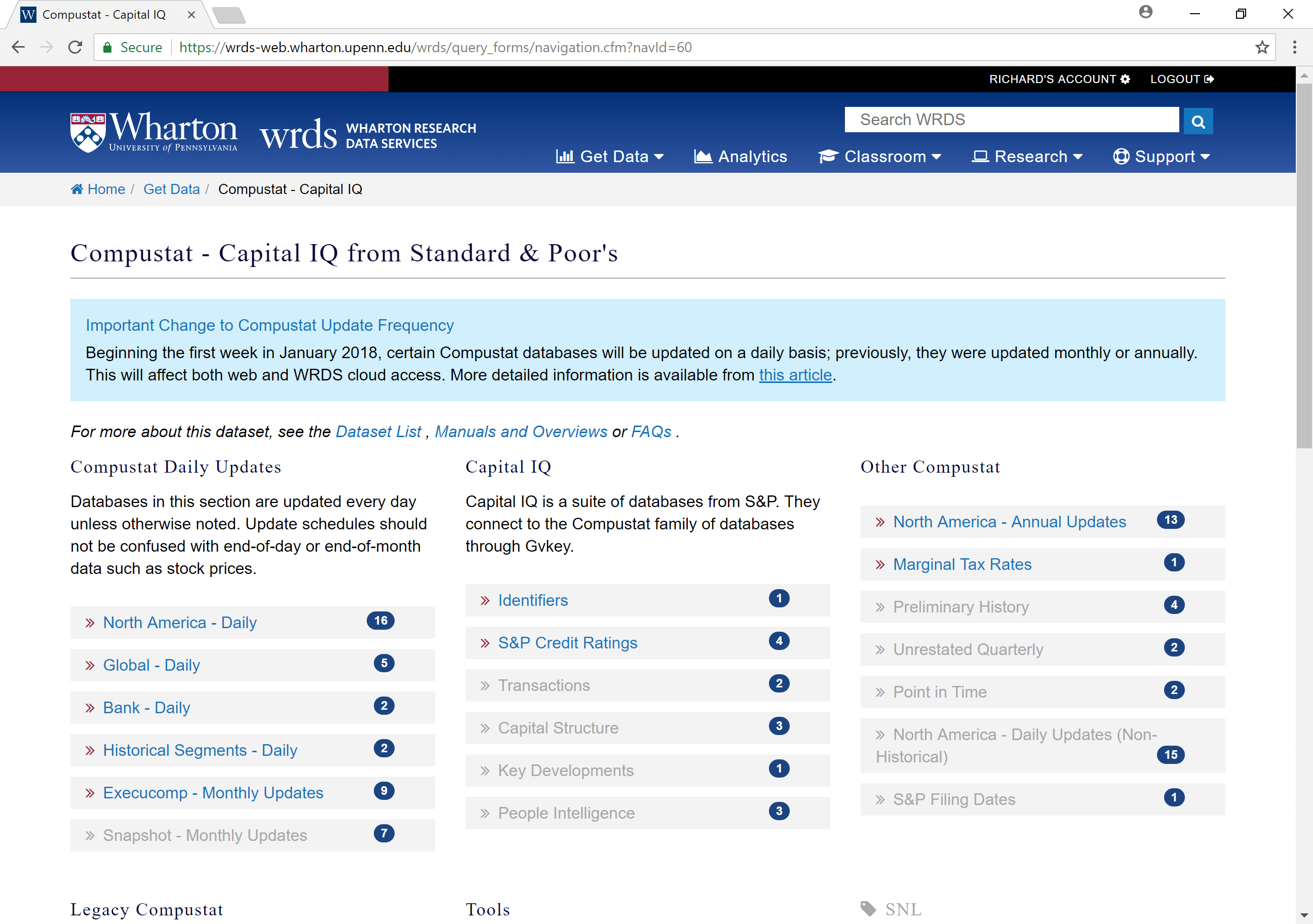
Pick a data set, e.g. “North America - Daily”
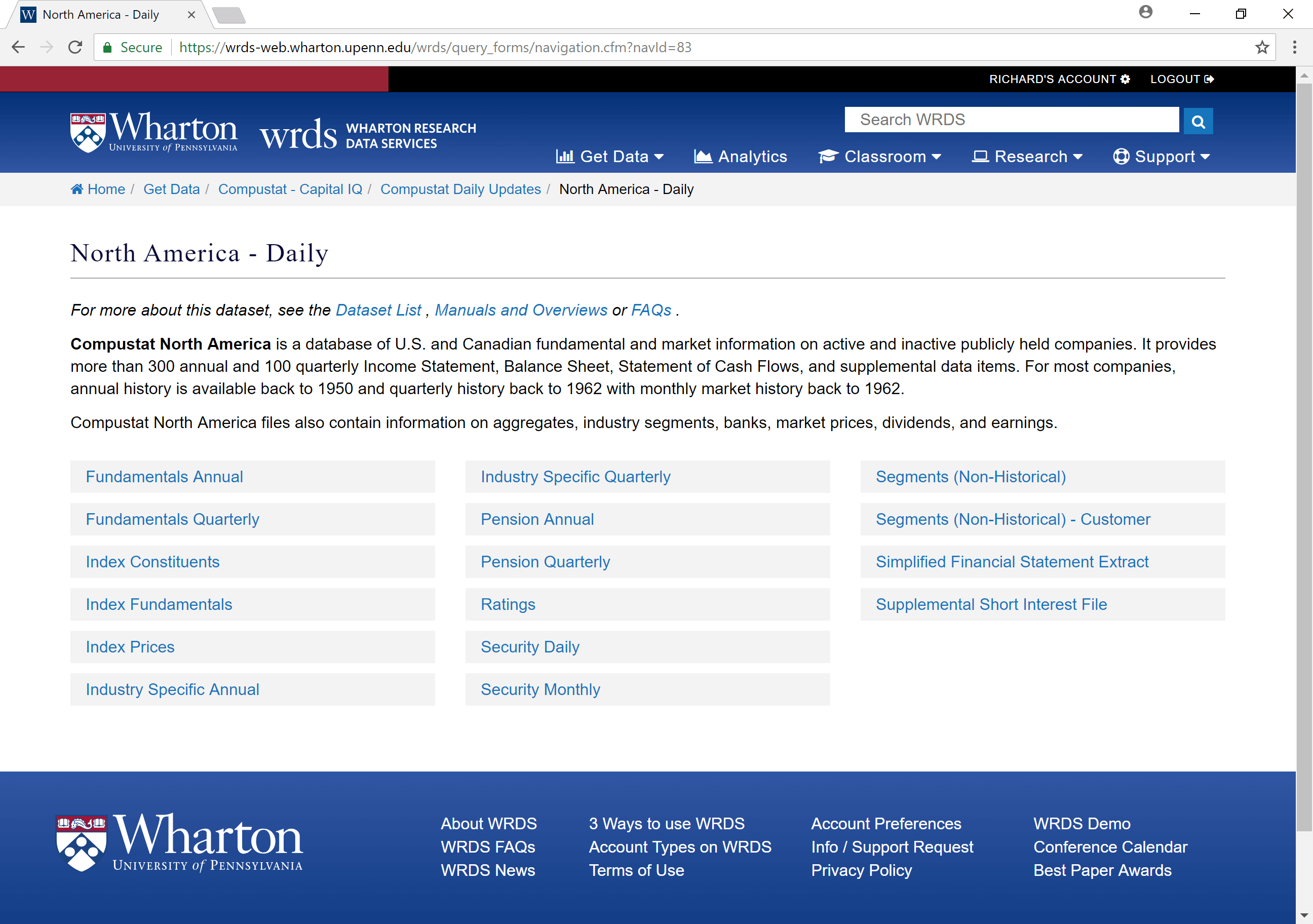
Pick a data set, e.g. “Fundamentals Annual”
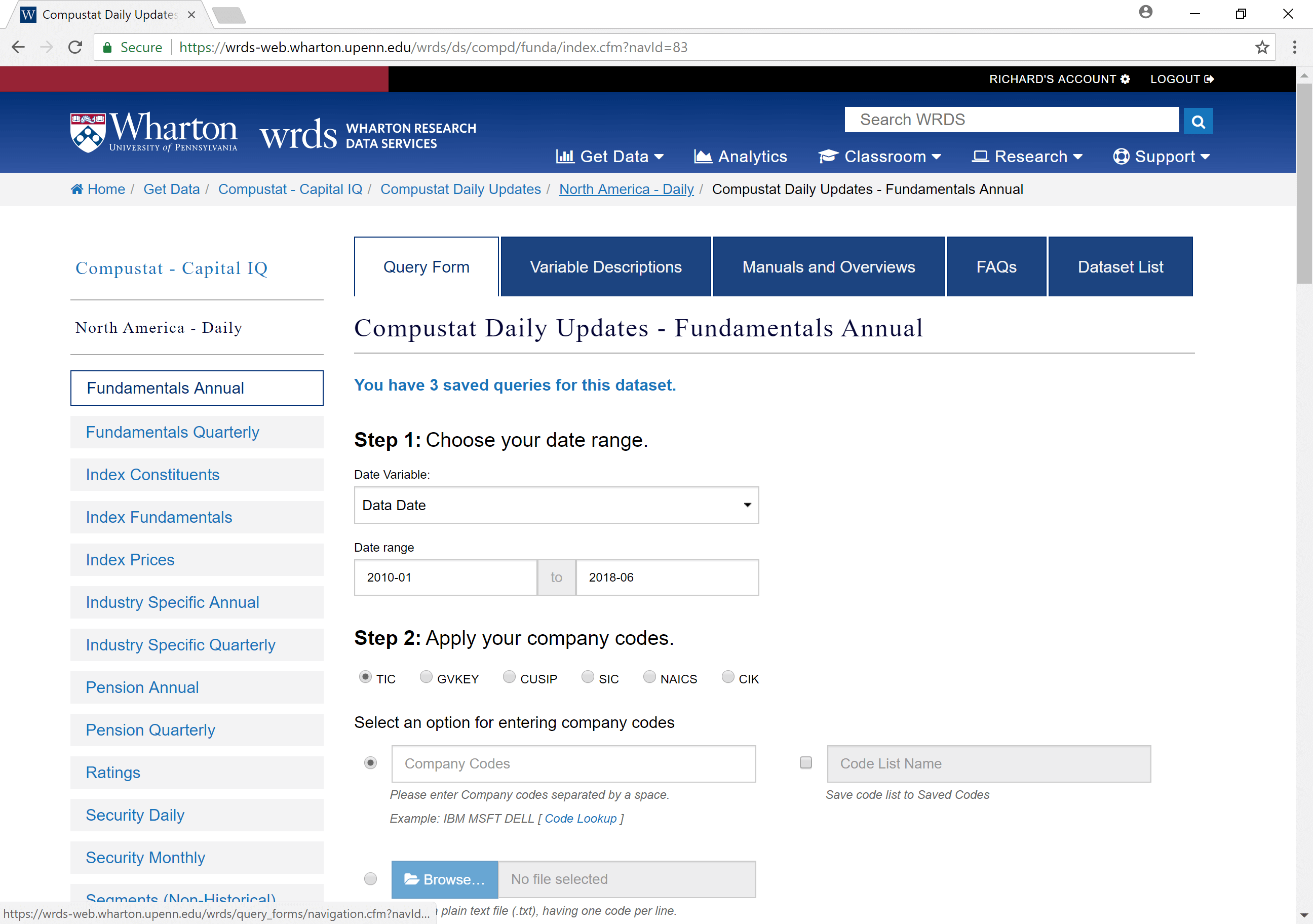
Selecting data: Time range
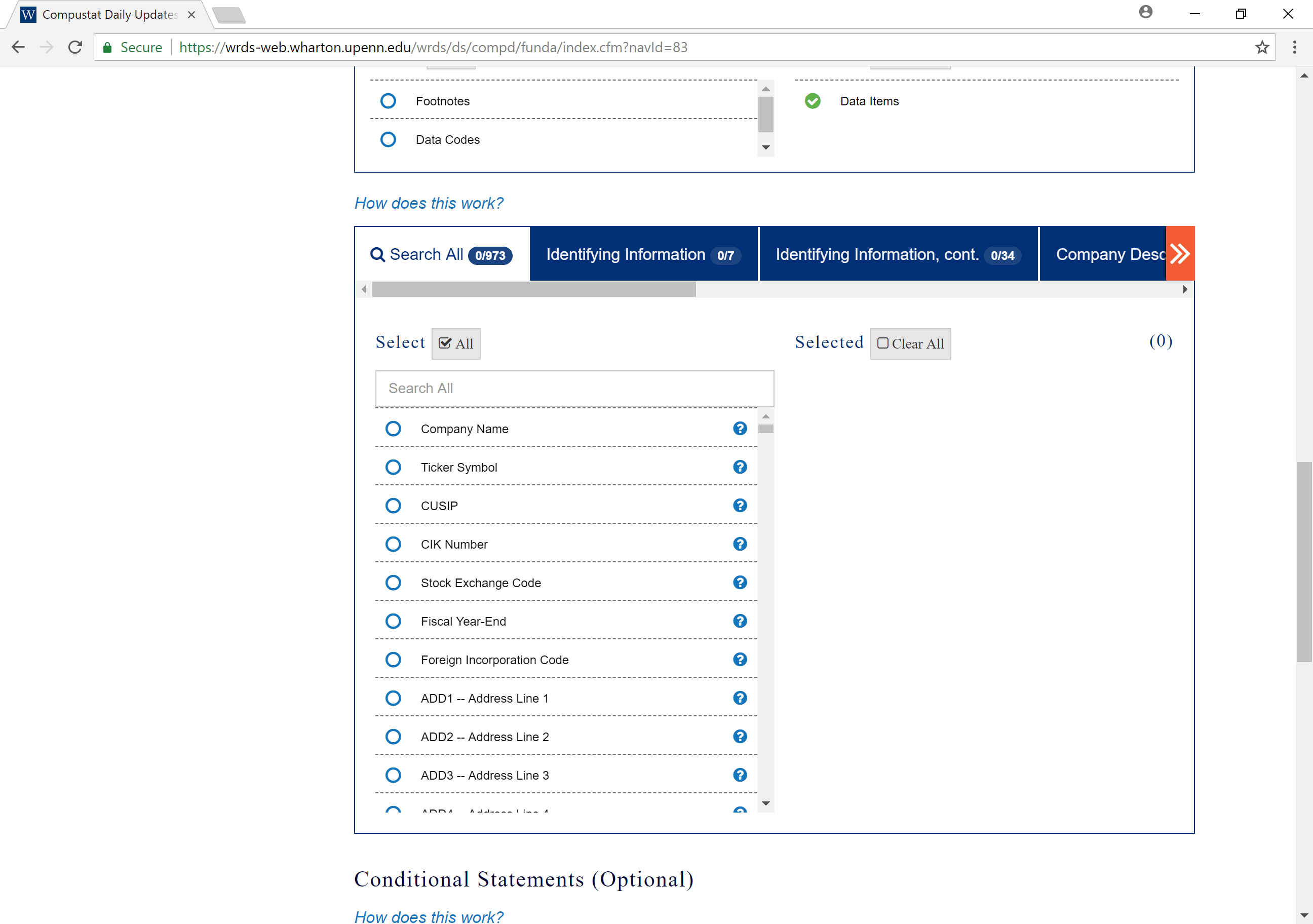
Selecting data fields
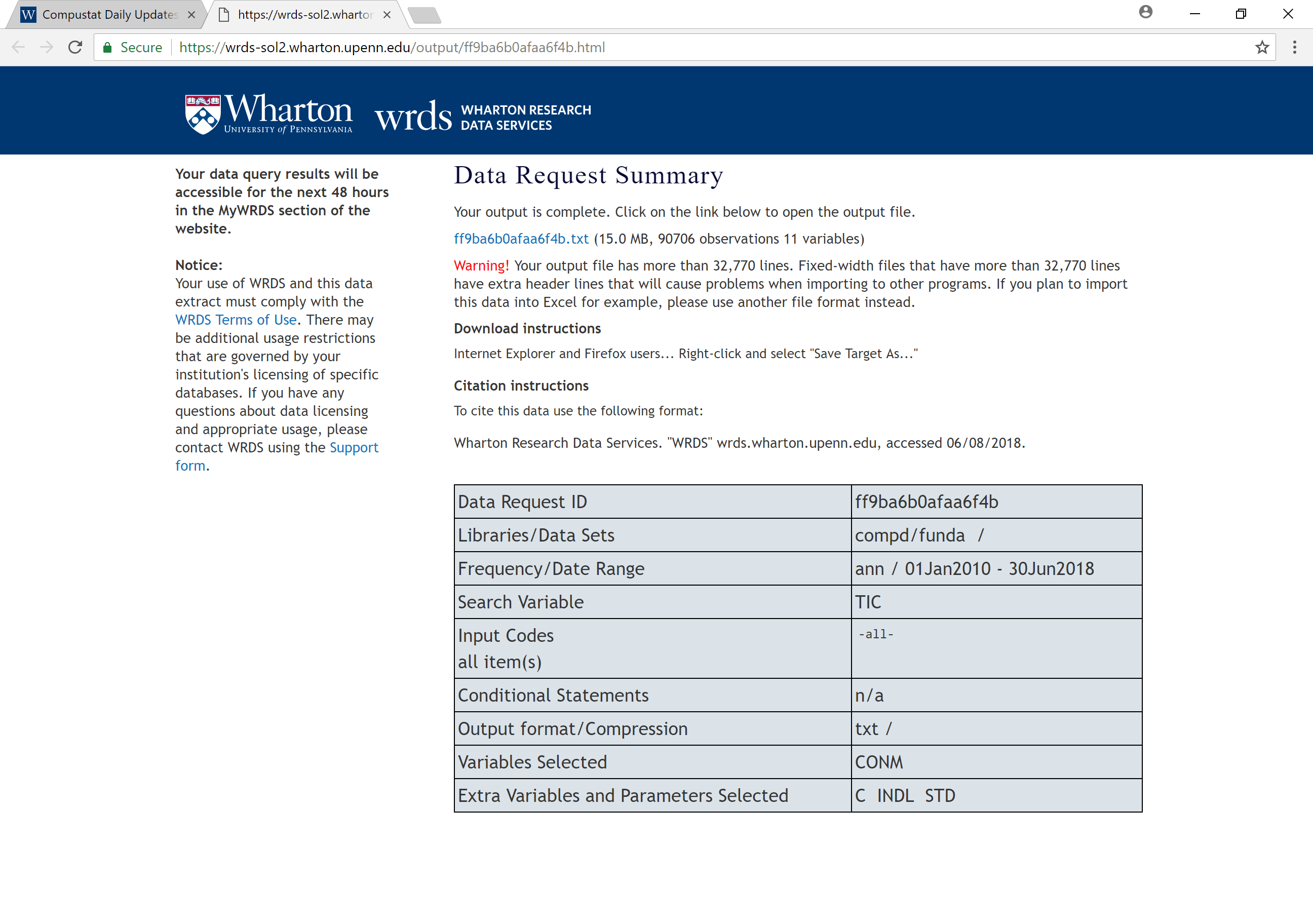
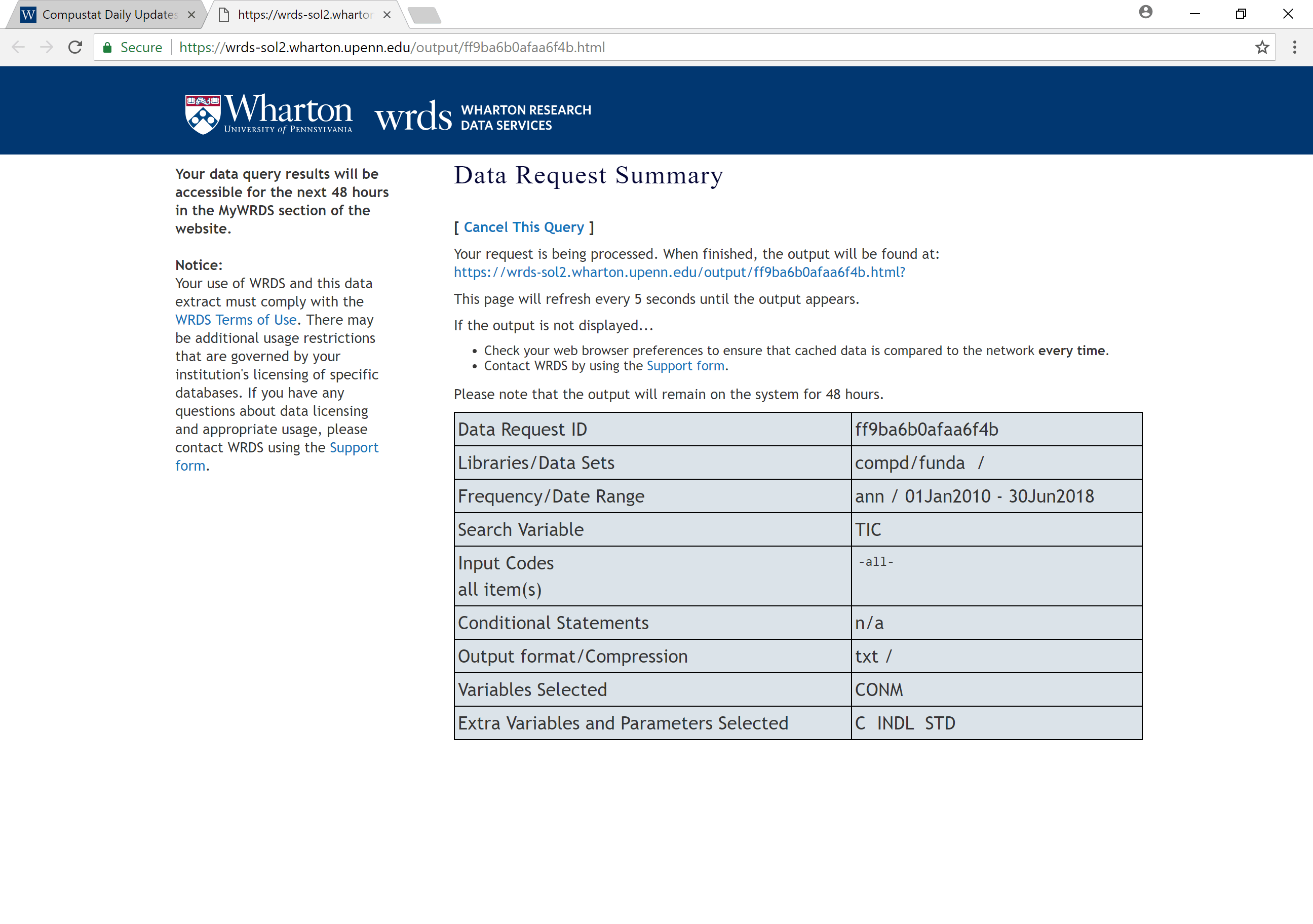
Wait for the data to be prepared
Download the data!